前言
本章的阅读无分先后,我们尽量用通俗的语言,典型的案例代码和模拟输出结果,帮助您快速掌握这些必知必会的概念和知识点,以便后续文档的阅读更加顺畅,二次开发的姿势更加准确。
表单验证
在表单操作的代码入口处,往往堆积着大量丑陋且臃肿的参数验证代码。在这里,我们使用 Hibernate Validator 框架帮助大家解决了这些问题。为了节省篇幅,文档中仅介绍与我们生成后代码有关的知识点,对于 Hibernate Validator 的更多了解,请自行百度。
所有 Hibernate Validator 注解及扩展注解均应用于 Dto 类的字段中。
内置注解
- @NotBlank。和 @NotNull 相比,最大的区别在于该注解用于字符型字段验证,具体说明见下面的代码及其注释。
/**
* 等同于 gradeName != null && gradeName != ""。
* 如验证失败,则返回message中的错误信息。
*/
@NotBlank(message = "数据验证失败,年级名称不能为空!")
private String gradeName;- @NotNull。和 @NotBlank 相比,通常用于非字符型对象。
/**
* 这里应用于Integer类型的字段。
*/
@NotNull(message = "数据验证失败,主键Id不能为空!")
private Integer statsId;
/**
* 这里应用于Date类型的字段。
*/
@NotNull(message = "数据验证失败,统计日期不能为空!")
private Date statsDate;- @Min/@Max,用于限制整型字段数值的最小值和最大值。
/**
* 等同于 loaderType >= 1 && loaderType <= 5。
* 如验证失败,则返回message中的错误信息。
*/
@Min(value = 1, message = "Job数据加载器类型不能低于最小值!")
@Max(value = 5, message = "Job数据加载器类型不能高于最大值!")
private Integer loaderType;- @Pattern,字符型字段的正则表达式验证。
/**
* 正则验证失败,返回message中的错误信息。
*/
@Pattern(regexp = "^[a-zA-Z][0-9a-zA-Z]+$",
message = "只能包含英文字母和数字,首字符必须为字母!")
private String variableName;扩展注解
- @ConstDictRef,该注解用于常量字典引用验证,标记的字段值必须是引用常量对象的合法值。
// 表示难度的常量字典对象。为了节省篇幅,注释和其他代码细节没有列出。
public final class Difficulty {
public static final int EASY = 0;
public static final int NORMAL = 1;
public static final int DIFFICULT = 2;
public static boolean isValid(int value) {
return DICT_MAP.containsKey(value);
}
... ...
}
/**
* constDictClass,指定待验证的常量字典对象的class。
* 字段difficulty的取值必须是Difficulty对象中声明的常量值。
*/
@ConstDictRef(constDictClass = Difficulty.class, message = "数据验证失败,习题难度为无效值!")
private Integer difficulty;- @TextLength,该注解用于验证 UTF-8 编码的字符型字段的字符长度。下面的注释中给出了具体的用法说明。
/**
* 英文字母和数字等ASCII字符的单位长度为1,UTF-8编码的中文字符单位长度也为1。
* 如:Hello老刘,长度为7。一旦大于10或小于1,则返回message中的错误信息。
*/
@TextLength(min = 1, max = 10, message = "数据验证失败,学生姓名字段长度无效!")
@TableField(value = "student_name")
private String studentName;验证分组
作为 @NotNull 和 @NotBlank 注解的 groups 参数,分组对象更进一步定义了具体的验证场景。我们缺省定义了 AddGroup 和 UpdateGroup 分组对象,这里仅以 UpdateGroup 为例讲述其应用场景,见如下代码和注释。
/**
* 1. courseId是主键字段,因此不能为空,这就需要用@NotNull/@NotBlank注解进行非空约束。
* 2. 表单的新增(add)接口中,前端无法提供主键值(后端负责生成),这该咋办?
* 3. 在新增接口中,@NotNull的groups参数什么都别传,主键的非空验证就会不起作用了。
* 4. 可是更新接口(update)却偏偏需要主键的非空验证,没有主键更新谁呢?
* 5. 在更新接口的验证中,把这个UpdateGroup分组作为参数传递进来,就起作用了。
*/
@NotNull(message = "数据验证失败,主键Id不能为空!", groups = {UpdateGroup.class})
private Long courseId;接口验证
前面讲述了如何定义验证注解,本小节将介绍如何在 Controller 接口中进行数据验证。结合上述代码,这里仅给出更新 (update) 接口的代码示例,请务必仔细阅读下面的代码和相关注释。
@PostMapping("/update")
public ResponseResult<Void> update(@MyRequestBody("course") CourseDto courseDto) {
// 1. courseDto为待验证的输入参数对象,对象字段中包含了这些验证注解。
// 2. Default.class和UpdateGroup.class是分组数组参数,验证的时候是会起作用的。
// 3. 由于主键courseId的注解定义为
// @NotNull(message = "主键Id不能为空!", groups = {UpdateGroup.class})
// 4. 既然验证函数中传入了UpdateGroup.class,那么当前验证就会生效。
// 5. 对于新增接口,不需要主键非空的验证起作用,那么调用验证函数时,就别传该参数。
//
// 最后说一下Default.class,Java Validation规范内置的分组对象。
// 1. 下面的注解中没有传入groups参数,因此都使用Default.class作为缺省分组。
// @NotNull(message = "数据验证失败,主键Id不能为空!")
// 2. 规则是验证时,如果传入groups,那么只有传入的分组起作用,否则就Default的起作用。
// 3. 更新接口的验证中,既然传入了UpdateGroup, 就必须也传入Default,否则缺省分组下
// 的验证注解不起作用。
// 4. 对于新增接口,没有传入任何group,那么仅有Default分组的验证起作用。如:
// errorMessage = MyCommonUtil.getModelValidationError(courseDto);
String errorMessage = MyCommonUtil.getModelValidationError(
courseDto, Default.class, UpdateGroup.class);
if (errorMessage != null) {
return ResponseResult.error(ErrorCodeEnum.DATA_VALIDATAED_FAILED, errorMessage);
}
... ...
return ResponseResult.success();
}参数解析
先明确一下,Spring Boot 自带的接口参数注解 @RequestParam、@RequestBody 和 @PathVariable 仍然可用。相比于它们,我们自定义的注解参数 @MyRequestBody 又有哪些优势呢。
自定义的优势
- 前后端更解耦,在约定范围内的参数变化,不会引起后端代码的联动修改。
- 请求参数反射实体字段时表述更准确,不会出现歧义。
- 可读性更高,无需使用 JSONObject 接收更复杂的参数对象。
应用示例
这里模拟的业务场景是,习题表 Exercise 是主表,知识点表 Knowledge 是主表的一对一从表。查询参数为习题表或知识点表中的字段,返回数据是过滤后的习题列表。在下面的代码片段中,共列出三种场景分别应对上述三种问题,请务必仔细阅读代码及其注释。
/**
* 第一种场景。HTTP请求参数为 exerciseId=1&knowledgeId=2&name=xxx。
* 显而易见的是,如果前端增加了过滤参数,后端的接口也需要跟着修改,这种接口定义方式,
* 前后端耦合性很强。
*/
@PostMapping("/list")
public ResponseResult<?> list(
@RequestParam Long exerciseId,
@RequestParam String name,
@RequestParam Long knowledgeId) {
// 这里忽略若干行参数验证... ...
List<Exercise> exerciseList =
service.getExerciseListWithRelation(exerciseId, name, knowledgeId);
return ResponseResult.success(MyPageUtil.makeResponseData(exerciseList));
}
/**
* 第二种场景。HTTP请求参数仍为 exerciseId=1&knowledgeId=2&name=xxx。
* 这里我们使用对象exerciseFilter和knowledgeFilter作为接口参数,从而解决了上述
* 场景中的耦合性问题。这一切都是Spring替我们完成的,他会根据参数的变量名,通过反射
* 的方式查找对象中是否存在同名的字段。如果存在就会为实例化后的参数对象进行赋值。
* 如: exerciseFilter.exerciseId = 1。我们试想一下,如果Exercise和Knowledge
* 对象中都包含name字段,结果是Spring会把name的参数值同时赋值给两个参数对象。
* 如: exercise.name = xxx and knowledge.name = xxx。
* 由于knowledge.name = xxx是多余条件,因此我们真正期望的数据被该条件过滤掉了。
*/
@PostMapping("/list")
public ResponseResult<?> list(
ExerciseDto exerciseFilter, KnowledgeDto knowledgeFilter) {
// 这里忽略若干行参数验证... ...
List<Exercise> exerciseList =
service.getExerciseListWithRelation(exerciseFilter, knowledgeFilter);
return ResponseResult.success(MyPageUtil.makeResponseData(exerciseList));
}
/**
* 第三种场景。HTTP请求参数改为JSON格式,
* {
* exericseFilter: {exerciseId: 1, name: xxx},
* knowledgeFilter: {knowledgeId: 2}
* }
* 结合@RequestBody注解,这种接口定义方式确实解决了前面两个问题。然而从下面的代码
* 中不难看出,我们必须额外声明一个class,同时包含这两个Filter字段。结果是我们不得
* 不为应对此种场景,声明更多的容器对象。当然也可以把当前服务中所有的Model都放到一
* 个上帝容器类中。^-^
* 另一种处理方式是使用Map或者JSONObject作为接口参数,因为可读性太低,所以不推荐了。
*/
@PostMapping("/list")
public ResponseResult<?> list(@RequestBody ExerciseAndKnowledge bossFilter) {
// 这里忽略若干行参数验证... ...
List<Exercise> exerciseList = service.getExerciseListWithRelation(
bossFilter.getExerciseFilter(), bossFilter.getKnowledgeFilter());
return ResponseResult.success(MyPageUtil.makeResponseData(exerciseList));
}
/**
* 第四种场景。HTTP请求参数改为JSON格式,
* {
* exericseFilter: {exerciseId: 1, name: xxx},
* knowledgeFilter: {knowledgeId: 2}
* }
* 解决方案呢,当然是使用我们的@MyRequestBody注解。是不是看上去很销魂。^-^
*/
@PostMapping("/list")
public ResponseResult<?> list(
@MyRequestBody ExerciseDto exerciseFilter,
@MyRequestBody KnowledgeDto knowledgeFilter) {
// 这里忽略若干行参数验证... ...
List<Exercise> exerciseList =
service.getExerciseListWithRelation(exerciseFilter, knowledgeFilter);
return ResponseResult.success(MyPageUtil.makeResponseData(exerciseList));
}应用限制
自定义注解 @MyRequestBody 在使用上又有哪些限制呢?
- 仅支持 POST 请求,且请求体必须为 JSON 格式。
- 在微服务应用中,该注解不能应用于 FeignClient 的接口参数。见如下代码,
// 这里是学生数据的远程调用接口定义,为了节省篇幅,注释和其他代码细节没有列出。
@FeignClient(
name = "upms",
configuration = FeignConfig.class,
fallbackFactory = StudentClient.StudentClientFallbackFactory.class)
public interface StudentClient extends BaseClient<StudentDto, Long> {
// queryParam参数只能被@RequestBody注解标记,不能被自定义注解@MyRequestBody标记。
@Override
@PostMapping("/student/listBy")
ResponseResult<List<StudentDto>> listBy(@RequestBody MyQueryParam queryParam);
... ...
}深入细节
在调用 Controller 接口前,Spring 会将 HTTP 请求中的参数信息反射为接口方法参数,这一过程是由参数解析器的 resolveArgument 方法实现的。我们在 CommonWebMvcConfig 配置类中,注册了自定义的参数解析器对象 MyRequestArgumentResolver,用于解析添加了 @MyRequestBody 注解的接口参数。具体解析逻辑可参考以下流程图。

对象转换
目前主要用于 Controller 中,将 Model 类型对象转换为 VO 类型对象,之后再返回给前端。
技术选型
MapStruct,为啥用它?
- 功能强大,无论对象还是集合,支持多种数据映射方式,可支持 Java 函数。
- 性能优势,没有反射,没有反射,没有反射。利用 Annotation Processor 特性,自动生成对象映射代码。
代码示例
对象映射的代码通常位于 Model 对象中,请留意下面的代码注释。
@Data
@TableName(value = "zz_course")
public class Course {
// 主键Id。
@TableId(value = "course_id")
private Long courseId;
// 这里为了节省篇幅,省去若干字段 ... ...
// java(mapToBean(courseDto.getTeacher(), ....TeacherDto.class))")
// java(), 表示里面调用的是Java方法。
// mapToBean和beanToMap都是基类BaseModelMapper中的方法,这里可以直接调用。
// mapToBean用于将Map类型参数courseDto.getTeacher(),转换为TeacherDto类型的bean。
// beanToMap功能和mapToBean完全相反,是bean转Map。可参考该函数的代码注释。
@Mapper
public interface CourseModelMapper extends BaseModelMapper<CourseDto, Course> {
CourseModelMapper INSTANCE = Mappers.getMapper(CourseModelMapper.class);
// 转换Dto对象到Model对象。
@Mapping(target = "teacher",
expression = "java(mapToBean(courseDto.getTeacher(), ....TeacherDto.class))")
@Override
Course toModel(CourseDto courseDto);
// 转换Model对象到Dto对象。
@Mapping(target = "teacher",
expression = "java(beanToMap(course.getTeacher(), false))")
@Override
CourseDto fromModel(Course course);
}
}下面看看我们在 Controller 中又是如何使用的。
/**
* 列出符合过滤条件的课程数据源列表。
*
* @param courseDtoFilter 过滤对象。
* @param orderParam 排序参数。
* @param pageParam 分页参数。
* @return 应答结果对象,包含查询结果集。
*/
@PostMapping("/list")
public ResponseResult<?> list(
@MyRequestBody("courseFilter") CourseDto courseDtoFilter,
@MyRequestBody MyOrderParam orderParam,
@MyRequestBody MyPageParam pageParam) {
// 1. 这里将Controller接口的DTO入参,转换为Model对象类型。
Course courseFilter =
Course.CourseModelMapper.INSTANCE.toModel(courseDtoFilter);
... ...
// 2. 这里将待返回给前端的Model类型对象列表,转换为DTO对象列表。
List<CourseDto> courseDtoList =
Course.CourseModelMapper.INSTANCE.fromModelList(courseList);
Tuple2<List<CourseDto>, Long> responseData =
new Tuple2<>(courseDtoList, totalCount);
return ResponseResult.success(MyPageUtil.makeResponseData(responseData));
}问题定位
既然 MapStruct 是基于 Annotation Processor 实现的,那么我们就可以在编译后生成的 target 目录下找到对应的实现类。这里以 Course 类的内部接口 CourseModelMapper 为例,见如下代码声明。
@Data
@TableName(value = "zz_course")
public class Course {
// 这里略过Course的若干字段 ... ...
@Mapper
public interface CourseModelMapper extends BaseModelMapper<CourseDto, Course> {
CourseModelMapper INSTANCE = Mappers.getMapper(CourseModelMapper.class);
}
}下图为 MapStruct 为我们生成的实现类 Course$CourseModelMapperImpl,请留意左侧红框中标记出的文件位置。

Knife4j 接口文档
一定要在配置工程属性时,选择支持「Knife4j接口文档框架」,否则不会生成 Swagger 相关的代码。 进行正确配置后,在项目生成时就已经完成了 pom 依赖和服务配置的正确设置。下面的内容,只是给大家介绍一下具体的集成方式,便于开发者日后的自行修改。
实现方式
- 单体服务。在 application 应用的 pom.xml 中引用 common-swagger 的依赖即可。
<dependency>
<groupId>com.orangeforms</groupId>
<artifactId>common-swagger</artifactId>
<version>1.0.0</version>
</dependency>- 微服务网关。 pom 中需集成 knife4j-gateway-spring-boot-starter 的依赖。
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-gateway-spring-boot-starter</artifactId>
<version>${knife4j.version}</version>
</dependency>- 微服务业务服务。需在每个业务服务 api 模块的 pom.xml 中,引用对 common-swagger 的依赖。
<dependency>
<groupId>com.orangeforms</groupId>
<artifactId>common-swagger</artifactId>
<version>1.0.0</version>
</dependency>配置方式
- 单体服务。在 applicaiton 应用的配置文件中 (resources/application.yml),包含以下配置信息。
common-swagger:
# 当enabled为false的时候,则可禁用swagger。
enabled: true
# 工程的基础包名。
basePackage: com.orangeforms
title: 橙单单体教学版
description: 橙单单体教学版详情
version: 1.0
springdoc:
swagger-ui:
path: /swagger-ui.html
tags-sorter: alpha
api-docs:
path: /v3/api-docs
default-flat-param-object: false- 微服务业务服务。在 application-dev.yaml 公用配置文件中,包含以下配置信息。可直接将该文档导入到 Nacos。
common-swagger:
# 当enabled为false的时候,则可禁用swagger。
enabled: true
# 工程的基础包名。
basePackage: com.orangeforms
title: 橙单单体教学版
description: 橙单单体教学版详情
version: 1.0- 微服务业务服务。在每个服务的配置文件中,如 upms-dev.yaml,包含以下配置信息。可直接将该文档导入到 Nacos。
springdoc:
swagger-ui:
path: /swagger-ui.html
tags-sorter: alpha
api-docs:
path: /admin/upms/v3/api-docs
default-flat-param-object: false- 微服务网关。在 gateway-dev.yaml 配置文件中,包含以下路由聚合配置信息。可直接将该文档导入到 Nacos。
knife4j:
gateway:
enable: true
routes:
# 页面显示的中文名
- name: 用户权限服务
# 下面示例中的/admin/upms为服务接口路径前缀
# 下面示例中的/v3/api-docs?group=default为固定值即可。
url: /admin/upms/v3/api-docs?group=default
# 微服务服务名,对比网关路由中的 uri: lb://upms
service-name: upms
# 显示顺序
order: 0
- name: 课程作业服务
url: /admin/coursepaper/v3/api-docs?group=default
service-name: course-paper
order: 1使用方式
- 在启动所有服务后,访问地址 http://localhost:8082/doc.html。
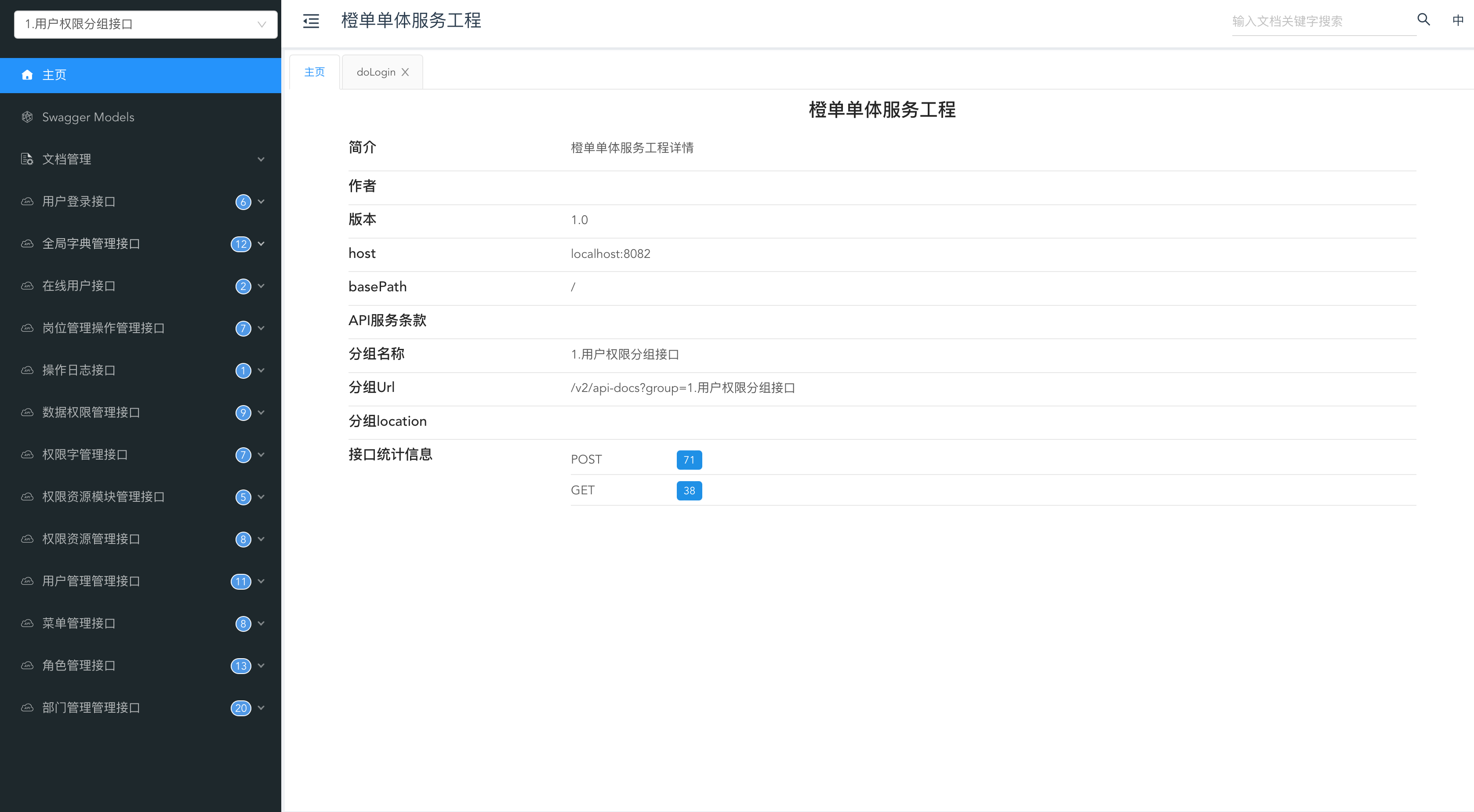
- 由于在 Knife4j 的调试页面中,无法输入验证码,因此需要修改登录接口代码,关闭验证码功能。
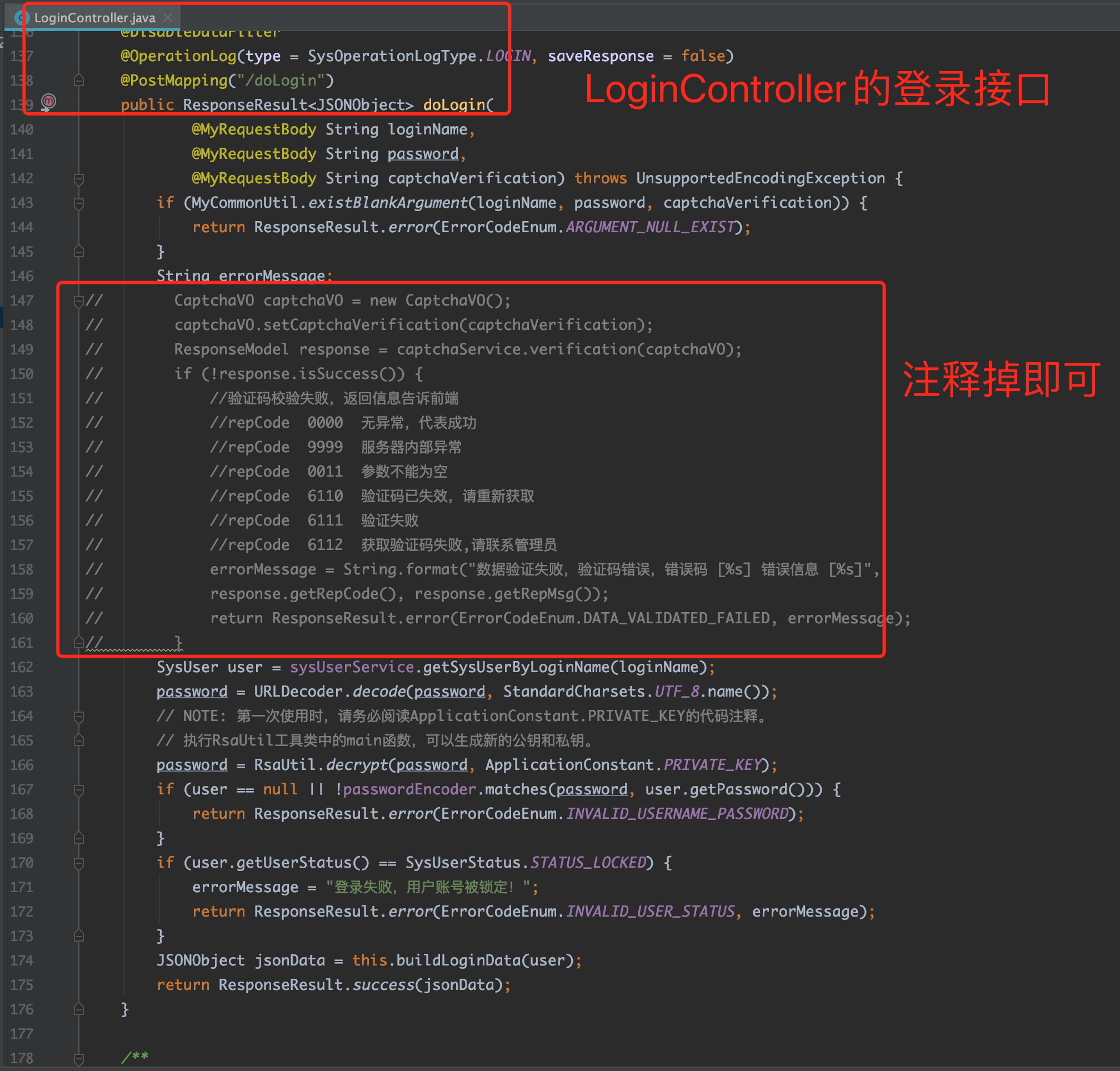
- 执行登录接口。为了便于您快速上手,我们在 Swagger 的注解代码中提供了 admin 用户的缺省密文。以下代码来自于 LoginController 文件,请留意注解中的注释说明。为了安全起见,也请您尽快更新您的私钥和公钥,具体生成方式可参考 开发环境部署章节的生成密钥段落小节。
@ApiImplicitParams({
// 这里包含密码密文,仅用于方便开发期间的接口测试,集成测试和发布阶段,需要将当前注解去掉。
@ApiImplicitParam(name = "loginName", defaultValue = "admin"),
@ApiImplicitParam(name = "password", defaultValue = "encryptPassword")
})
@GetMapping("/doLogin")
public ResponseResult<JSONObject> doLogin(
@MyRequestBody String loginName,
@MyRequestBody String password,
@MyRequestBody String captchaVerification) throws UnsupportedEncodingException {
// 忽略具体实现代码 ... ...
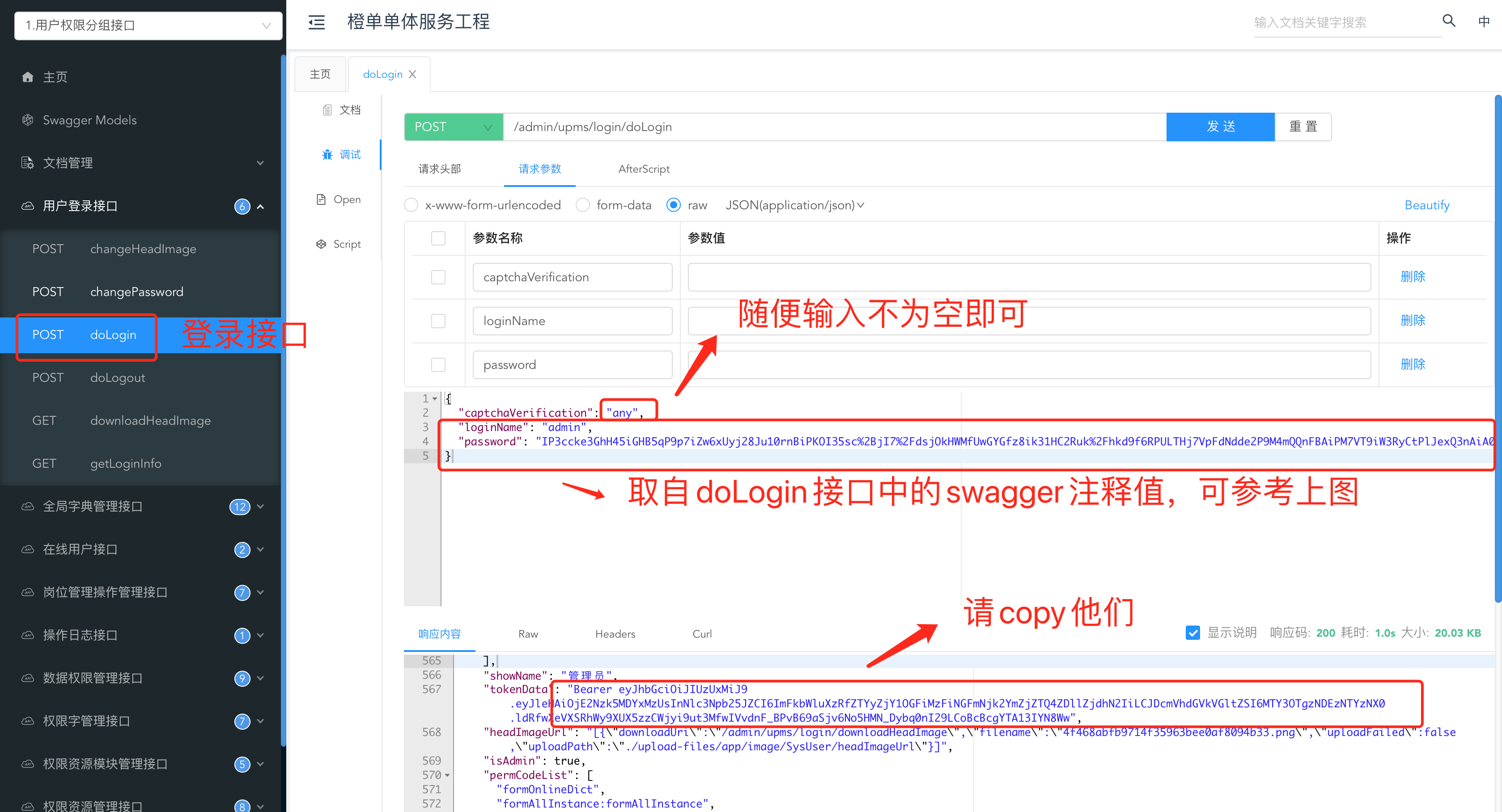
} - 调用 doLogin 接口,并获取 JWT Token。见下图及其注释。
- 创建全局变量,并将上一步中的 Token 值,粘贴过来。见下图及其注释。
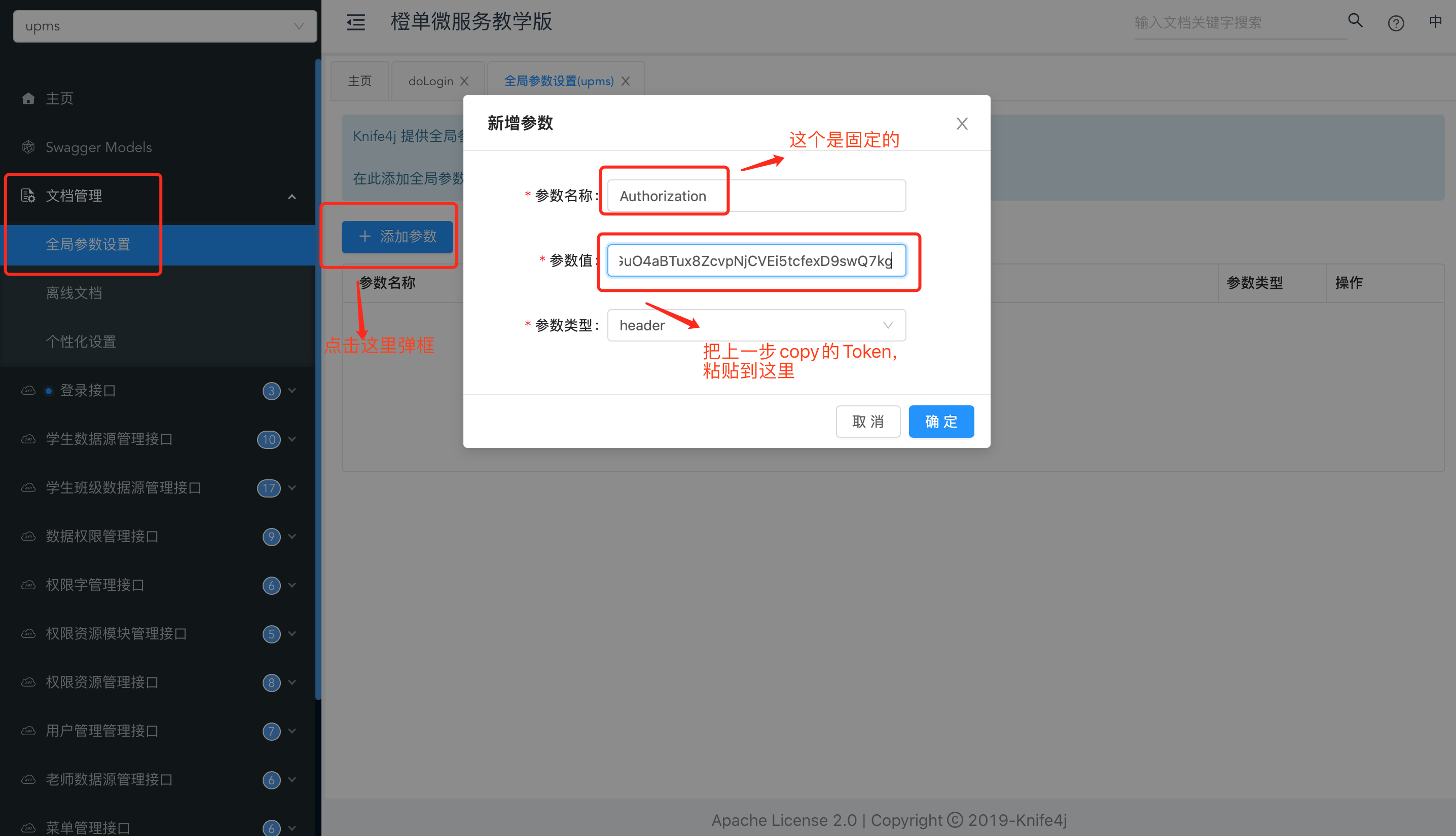
- 操作到这里,就可以执行任何其他接口了。见下图及其注释。

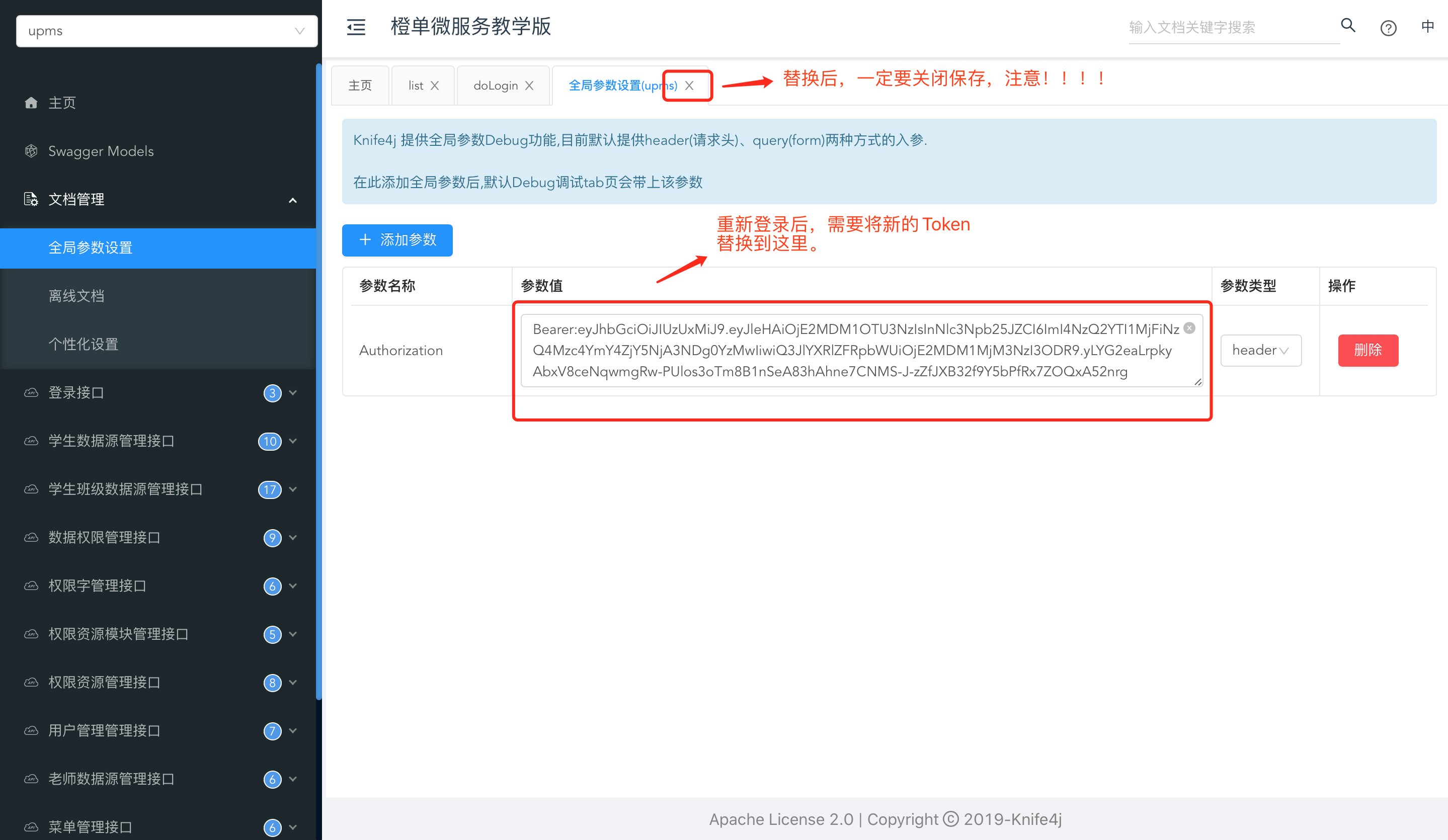
- 修改 JWT Token 的注意事项。很关键,否则出错你得找半天。见下图及其注释。
核心插件
写在本篇内容的最后,希望对有兴趣研究 Swagger 插件的同学,能有一些启发和帮助。非常感谢 Knife4j 作者 @八一菜刀 的全力帮助,橙单基于 Swagger 的扩展插件均由 Knife4j 作者提供,再次感谢作者将 Swagger 增强的如此接地气且实用,推荐 Knife4j。
核心注解
本节介绍的注解含义简单、直观,无需太多的应用上下文支持即可看懂。因此建议大家先行了解他们的用途,以便后续的文档和代码阅读更加顺畅。
UploadFlagColumn
数据上传字段,标记于数据实体对象的字段上。该字段的数据保存了数据文件存储的信息,以便于下载和预览时使用。请看如下代码示例,并特别留意 pictureUrl 字段上的关键注释。
@TableName(value = "zz_course")
public class Course {
// 主键Id。
@TableId(value = "course_id")
private Long courseId;
// 课程名称。
@TableField(value = "course_name")
private String courseName;
// 多张课程图片地址。
// 仅需设置 storeType = UploadStoreTypeEnum.LOCAL_SYSTEM,就可以存储到本地。
@UploadFlagColumn(storeType = UploadStoreTypeEnum.LOCAL_SYSTEM)
@TableField(value = "picture_url")
private String pictureUrl;
// 中间忽略若干字段 ... ...
} 存储类型目前已支持 LOCAL_SYSTEM、MINIO_SYSTEM、ALIYUN_OSS_SYSTEM、QCLOUD_COS_SYSTEM 和 HUAWEI_OBS_SYSTEM 五种存储系统。在数据上传和下载的接口逻辑中,均会首先判断请求的字段是否包含该注解,这样可以极大的减少上传下载代码中,基于 HardCode 的硬编码逻辑。同时也能有效的避免因字段名变更而引发的低级错误。见如下上传接口代码及其注释。
/**
* 文件上传操作。
*
* @param fieldName 上传文件名。
* @param asImage 是否作为图片上传。如果是图片,今后下载的时候无需权限验证。否则就是附件上传,下载时需要权限验证。
* @param uploadFile 上传文件对象。
*/
@PostMapping("/upload")
public void upload(
@RequestParam String fieldName,
@RequestParam Boolean asImage,
@RequestParam("uploadFile") MultipartFile uploadFile) throws Exception {
UploadStoreInfo storeInfo = MyModelUtil.getUploadStoreInfo(Video.class, fieldName);
// 这里就会判断参数中指定的字段,是否支持上传操作。
if (!storeInfo.isSupportUpload()) {
ResponseResult.output(HttpServletResponse.SC_FORBIDDEN,
ResponseResult.error(ErrorCodeEnum.INVALID_UPLOAD_FIELD));
return;
}
// 根据字段注解中的存储类型,通过工厂方法获取匹配的上传下载实现类,从而解耦。
BaseUpDownloader upDownloader =
upDownloaderFactory.get(storeInfo.getStoreType());
UploadResponseInfo responseInfo = upDownloader.doUpload(null,
appConfig.getUploadFileBaseDir(), Video.class.getSimpleName(), fieldName, asImage, uploadFile);
// 忽略若干字段 ... ...
}RelationGlobalDict
全局编码字典关联。标记于主表实体对象的「关联结果」字段上,该字段必须同时被 @TableField(exist = false) 注解标记。如下面代码中 subjectIdDictMap 字段。注解 masterIdField 参数指定了当前类的关联字段,这里是 subjectId,而 dictCode 参数指定了关联字典的编码值,如 subject。
@Data
@TableName(value = "zz_course")
public class Course {
// 主键Id。
@TableId(value = "course_id")
private Long courseId;
// 中间忽略若干字段 ... ...
// 学科Id。
@TableField(value = "subject_id")
private Integer subjectId;
@RelationGlobalDict(
masterIdField = "subjectId",
dictCode = "subject")
@TableField(exist = false)
private Map<String, Object> subjectIdDictMap;
}下面是全局编码字典表 zz_global_dict 的示例数据,其中包含上面代码示例中引用的「dict_code = subject」的编码字典。
| dict_id | dict_code | dict_name | ... ... | deleted_flag |
|---|---|---|---|---|
| 1 | grade | 年级字典 | 1 | |
| 2 | subject | 学科字典 | 1 |
下面是全局编码字典数据表 zz_global_dict_item 的示例数据。
| id | dict_code | item_id | item_name | show_order | status | deleted_flag |
|---|---|---|---|---|---|---|
| 1 | subject | 0 | 英语 | 1 | 0 | 1 |
| 2 | subject | 1 | 数学 | 2 | 0 | 1 |
| 3 | subject | 2 | 语文 | 3 | 0 | 1 |
| 4 | subject | 3 | 物理 | 4 | 0 | 1 |
下面我们假设 zz_course 表中存在三条数据,见下表。
| course_id | course_name | ... ... | subject_id |
|---|---|---|---|
| 1000 | 高一数学 | ... ... | 1 |
| 1001 | 高二数学 | ... ... | 1 |
| 1002 | 高一英语 | ... ... | 0 |
获取数据库结果集,并在后台服务程序的内存中,通过 Java 代码将实体对象与常量字典进行数据关联,关联后的 JSON 格式数据和关键注释如下。
[
{
courseId: 1000,
courseName: "高一数学",
subjectId: 1,
// 下面的id和name是固定的key名称,分别关联到字典key和字典显示名称。
subjectIdDictMap: {
id: 1,
name: "数学"
}
},
{
courseId: 1001,
courseName: "高二数学",
subjectId: 1,
subjectIdDictMap: {
id: 1,
name: "数学"
}
},
{
courseId: 1002,
courseName: "高一语文",
subjectId: 0,
subjectIdDictMap: {
id: 0,
name: "英语"
}
}
]RelationConstDict
常量字典数据关联。标记于主表实体对象的「关联结果」字段上,该字段必须同时被 @TableField(exist = false) 注解标记。如下面代码中 subjectIdDictMap 字段。注解 masterIdField 参数指定了当前类的关联字段,这里是 subjectId,而 constantDictClass 参数指定了关联的常量字典对象,如 Subject。
@Data
@TableName(value = "zz_course")
public class Course {
// 主键Id。
@TableId(value = "course_id")
private Long courseId;
// 中间忽略若干字段 ... ...
// 学科Id。
@ConstDictRef(constDictClass = Subject.class, message = "数据验证失败,学科Id为无效值!")
@TableField(value = "subject_id")
private Integer subjectId;
@RelationConstDict(
masterIdField = "subjectId",
constantDictClass = Subject.class)
@TableField(exist = false)
private Map<String, Object> subjectIdDictMap;
}
// 为了节省篇幅,这里仅给出Subject对象中的必要代码。
public final class Subject {
// 语文。
public static final int CHINESE = 0;
// 数学。
public static final int MATH = 1;
// 英语。
public static final int ENGLISH = 2;
public static final Map<Object, String> DICT_MAP = new HashMap<>(3);
static {
DICT_MAP.put(CHINESE, "语文");
DICT_MAP.put(MATH, "数学");
DICT_MAP.put(ENGLISH, "英语");
}
// 后面略去更多代码 ... ...
}下面我们假设 zz_course 表中存在三条数据,见下表。
| course_id | course_name | ... ... | subject_id |
|---|---|---|---|
| 1000 | 高一数学 | ... ... | 1 |
| 1001 | 高二数学 | ... ... | 1 |
| 1002 | 高一语文 | ... ... | 0 |
获取数据库结果集,并在后台服务程序的内存中,通过 Java 代码将实体对象与常量字典进行数据关联,关联后的 JSON 格式数据和关键注释如下。
[
{
courseId: 1000,
courseName: "高一数学",
subjectId: 1,
// 下面的id和name是固定的key名称,分别关联到字典key和字典显示名称。
subjectIdDictMap: {
id: 1,
name: "数学"
}
},
{
courseId: 1001,
courseName: "高二数学",
subjectId: 1,
subjectIdDictMap: {
id: 1,
name: "数学"
}
},
{
courseId: 1002,
courseName: "高一语文",
subjectId: 0,
subjectIdDictMap: {
id: 0,
name: "语文"
}
}
]所有的变量命名和数据组装规则,都是前后端共同约定的。后台只需按照既定的规则输出数据,前端自然就可以正确的解析并显示数据。
RelationDict
数据表字典数据关联。标记于主表实体对象的「关联结果」字段上,该字段必须同时被 @TableField(exist = false) 注解标记。如下面代码中的 gradeIdDictMap 字段,由于该注解参数较多,因此每个参数的说明,已在下面的代码注释中给出,请务必仔细阅读并完全理解代码中的注释部分。
// BaseDictService的子类,会在服务启动时将字典表数据全部加载并缓存。
// 微服务缓存到redis中,单体服务可以缓存到redis,也可以缓存到本地内存。
@Service
public class GradeService extends BaseDictService<Grade, GradeDto, Integer> {
@Autowired
private GradeMapper gradeMapper;
@Autowired
private RedissonClient redissonClient;
@PostConstruct
public void init() {
this.dictionaryCache = RedisDictionaryCache.create(
redissonClient, "Grade", Grade.class, Grade::getGradeId);
}
}
@Data
@TableName(value = "zz_course")
public class Course {
// 主键Id。
@TableId(value = "course_id")
private Long courseId;
// 年级Id。
@TableField(value = "grade_id")
private Integer gradeId;
// 中间忽略若干字段 ... ...
// 一对一从表关联,后面会介绍的。这里之所以提前给出代码,是为了配合下面的
// teacherIdDictMap字典关联字段中的equalOneToOneRelationField参数。
// 提前说明的是,在进行数据组装时,一对一从表数据组装要先于字典数据组装。
@RelationOneToOne(
masterIdField = "teacherId",
slaveClientClass = TeacherClient.class,
slaveModelClass = TeacherDto.class,
slaveIdField = "teacherId")
@TableField(exist = false)
private TeacherDto teacher;
@RelationDict(
masterIdField = "gradeId", // 指定当前类的gradeId字段作为关联字段。
slaveServiceName = "gradeService", // 通过名称为gradeService的bean实例获取Grade数据。
slaveModelClass = Grade.class, // 关联字典数据的对象类型。
slaveIdField = "gradeId", // Grade对象的gradeId字段作为关联字段。
slaveNameField = "gradeName") // Grade对象的gradeName字段作为关联后的显示字段。
@TableField(exist = false)
private Map<String, Object> gradeIdDictMap;
// 这里只注释出与gradeIdDictMap有差异的注解参数。
// 先重点说一下equalOneToOneRelationField参数。
// 一对一从表的数据组装要先于字典数据组装。
// teacher字段和teacherIdDictMap字段,都是基于teacherId去关联的。
// 关联的都是远程TeacherClient接口中的数据。
// 当组装teacherIdDictMap关联字段时,teacher对象中已经包含了所需的数据。
// 因此teacherIdDictMap的关联数据,从teacher对象中获取即可。
// 节省了一次远程调用,这是一个非常有价值的优化。
@RelationDict(
masterIdField = "teacherId",
slaveClientClass = TeacherClient.class,// 通过FeignClient调用远程服务接口获取数据。
equalOneToOneRelationField = "teacher",
slaveModelClass = TeacherDto.class, // 因为是远程对象,所以使用Dto。
slaveIdField = "teacherId",
slaveNameField = "teacherName")
@TableField(exist = false)
private Map<String, Object> teacherIdDictMap;
}
// 年级表是典型的字典表,Id为自增主键,Name为显示名称。
@Data
@TableName(value = "zz_grade")
public class Grade {
// 主键Id。
@TableId(value = "grade_id")
private Integer gradeId;
// 年级名称。
@TableField(value = "grade_name")
private String gradeName;
}年级字典表的数据集为。
| grade_id | grade_name |
|---|---|
| 1 | 一年级 |
| ... ... | ... ... |
| 10 | 高一 |
| 11 | 高二 |
| 12 | 高三 |
老师表的数据集为。
| teacher_id | teacher_name | ... ... |
|---|---|---|
| 101 | 王老师 | ... ... |
| ... ... | ... ... | ... ... |
| 201 | 张老师 | ... ... |
| 202 | 李老师 | ... ... |
| ... ... | ... ... | ... ... |
下面我们假设 zz_course 表中存在三条数据,见下表。
| course_id | course_name | ... ... | grade_id | teacher_id |
|---|---|---|---|---|
| 1000 | 高一数学 | ... ... | 10 | 201 |
| 1001 | 高二数学 | ... ... | 11 | 201 |
| 1002 | 高一语文 | ... ... | 10 | 202 |
获取数据库结果集,并在后台服务程序的内存中,通过 Java 代码将实体对象与字典表数据进行关联,其中字典表数据采用 IN LIST 方式一次性读取,因此性能更高。下面是关联后的 JSON 格式数据和关键注释。
[
{
courseId: 1000,
courseName: "高一数学",
gradeId: 10,
// 下面的id和name是固定的key名称,分别关联到字典key和字典显示名称。
gradeIdDictMap: {
id: 10,
name: "高一"
},
teacherId: 201,
teacher: {
teacherId: 201,
teacherName: "田老师",
... ...
},
teacherIdDictMap: {
id: 201,
name: "田老师"
}
},
{
courseId: 1001,
courseName: "高二数学",
gradeId: 11,
gradeIdDictMap: {
id: 11,
name: "高"
},
teacherId: 201,
teacher: {
teacherId: 201,
teacherName: "张老师",
... ...
},
teacherIdDictMap: {
id: 201,
name: "张老师"
}
},
{
courseId: 1002,
courseName: "高一语文",
gradeId: 10,
gradeIdDictMap: {
id: 10,
name: "高一"
},
teacherId: 202,
teacher: {
teacherId: 202,
teacherName: "李老师",
... ...
},
teacherIdDictMap: {
id: 202,
name: "李老师"
}
}
]数据组装和输出规则与常量字典完全相同,不同的是常量字典的数据来自于 Java 代码声明,效率更高,但是不会动态变化。数据表字典的数据可能随时发生变化,如何维护变化的数据和缓存的一致性,请参考 架构进阶必读章节的字典缓存小节。
RelationOneToOne
一对一从表数据关联。标记于主表实体对象的「关联结果」字段上,该字段必须同时被 @TableField(exist = false) 注解标记。如下面代码中的 teacher 字段,由于该注解参数较多,因此每个参数的说明,已在下面的代码注释中给出,请务必仔细阅读并完全理解代码中的注释部分。
与字典关联字段 (Map类型) 不同的是,一对一关联结果字段的类型为从表的实体对象类型。另一个需突出强调的问题是,在为主表组装各种关联数据时,一对一从表组装要早于字典数据组装。
@Data
@TableName(value = "zz_course")
public class Course {
// 主键Id。
@TableId(value = "course_id")
private Long courseId;
// 主讲老师Id。
@TableField(value = "teacher_id")
private Long teacherId;
// 所属校区。
@TableField(value = "school_id")
@DeptFilterColumn
private Long schoolId;
// 中间忽略若干字段 ... ...
@RelationOneToOne(
masterIdField = "teacherId", // 指定当前类的teacherId字段作为关联字段。
slaveClientClass = TeacherClient.class, // 通过FeignClient获取远程服务接口数据。
slaveModelClass = TeacherDto.class, // 远程Dto对象类型。
slaveIdField = "teacherId") // 从表中的关联字段名称。
@TableField(exist = false)
private TeacherDto teacher;
@RelationOneToOne(
masterIdField = "schoolId", // 指定当前类的teacherId字段作为关联字段。
slaveServiceName = "sysDeptService", // 通过名称为sysDeptService的bean实例获取从表数据。
slaveModelClass = SysDept.class, // 从表实体对象类型
slaveIdField = "deptId") // 从表中的关联字段名称。
@TableField(exist = false)
private SysDept school;
}
@Data
@TableName(value = "zz_sys_dept")
public class SysDept {
// 部门Id。
@TableId(value = "dept_id")
private Long deptId;
// 部门名称。
@TableField(value = "dept_name")
private String deptName;
// 这里为了节省篇幅,省去若干字段 ... ...
}
@Data
@TableName(value = "zz_teacher")
public class Teacher {
// 主键Id。
@TableId(value = "teacher_id")
private Long teacherId;
// 教师名称。
@TableField(value = "teacher_name")
private String teacherName;
// 这里为了节省篇幅,省去若干字段 ... ...
}校区表的数据集。
| school_id | school_name | ... ... |
|---|---|---|
| 10 | 海淀校区 | ... ... |
| 11 | 西城校区 | ... ... |
| 12 | 朝阳校区 | ... ... |
| ... ... | ... ... | ... ... |
老师表的数据集。
| teacher_id | teacher_name | ... ... |
|---|---|---|
| 101 | 王老师 | ... ... |
| ... ... | ... ... | ... ... |
| 201 | 张老师 | ... ... |
| 202 | 李老师 | ... ... |
| ... ... | ... ... | ... ... |
下面我们假设 zz_course 表中存在三条数据,见下表。
| course_id | course_name | ... ... | school_id | teacher_id |
|---|---|---|---|---|
| 1000 | 高一数学 | ... ... | 10 | 201 |
| 1001 | 高二数学 | ... ... | 11 | 201 |
| 1002 | 高一语文 | ... ... | 10 | 202 |
获取数据库结果集,并在后台服务程序的内存中,通过 Java 代码将实体对象与从表数据进行关联,其中从表数据采用 IN LIST 方式一次性读取,因此性能更高。下面是关联后的 JSON 格式数据和关键注释。
[
{
courseId: 1000,
courseName: "高一数学",
schoolId: 10,
school: {
deptId: 10,
deptName: "海淀校区"
},
teacherId: 201,
teacher: {
teacherId: 201,
teacherName: "田老师",
... ...
}
},
{
courseId: 1001,
courseName: "高二数学",
schoolId: 11,
school: {
deptId: 11,
deptName: "西城校区"
},
teacherId: 201,
teacher: {
teacherId: 201,
teacherName: "张老师",
... ...
}
},
{
courseId: 1002,
courseName: "高一语文",
schoolId: 10,
school: {
deptId: 10,
deptName: "海淀校区"
},
teacherId: 202,
teacher: {
teacherId: 202,
teacherName: "李老师",
... ...
}
}
]RelationOneToMany
一对多数据关联。标记于主表实体对象的「一对多从表对象List」字段上,该字段必须同时被 @TableField(exist = false) 注解标记。
@Data
@TableName(value = "zz_course")
public class Course {
// 主键Id。
@ApiModelProperty(value = "主键Id", required = true)
@TableId(value = "course_id")
private Long courseId;
// 中间忽略若干字段 ... ...
@RelationOneToMany(
masterIdField = "courseId", // 指定当前类的courseId字段作为关联字段。
slaveServiceName = "courseSectionService",// 通过名称为courseSectionService的bean实例获取从表数据。
slaveModelClass = CourseSection.class, // 从表实体对象类型。
slaveIdField = "courseId") // 从表中的关联字段名称。
@TableField(exist = false)
private List<CourseSection> courseSectionList;
}RelationManyToMany
多对多中间表关联。标记于主表实体对象的「多对多关联对象List」字段上,该字段必须同时被 @TableField(exist = false) 注解标记。见如下代码中的 sysRoleMenuList 字段,同时请仔细阅读相关注释。
@Data
@TableName(value = "zz_sys_role")
public class SysRole {
// 主键Id。
@TableId(value = "role_id")
private Long roleId;
// 角色名称。
@TableField(value = "role_name")
private String roleName;
// 中间忽略若干字段 ... ...
@RelationManyToMany(
relationMapperName = "sysRoleMenuMapper", // 中间表的Mapper类
relationMasterIdField = "roleId", // 中间表关联主表的字段名
relationModelClass = SysRoleMenu.class) // 中间表实体对象类
@TableField(exist = false)
private List<SysRoleMenu> sysRoleMenuList;
}该注解标记的字段只会在服务类的 getByIdWithRelation 方法中被组装,既仅当调用主表的 view 接口并返回单条记录时,才可能调用服务类的 getByIdWithRelation 方法。相反,主表的 list 接口,通常不会也不需要组装该注解标记的字段。具体场景可见 SysMenuController.view 接口。请务必认真阅读下面 SysRoleController.view 接口的代码注释。
@GetMapping("/view")
public ResponseResult<SysRole> view(@RequestParam Long roleId) {
if (MyCommonUtil.existBlankArgument(roleId)) {
return ResponseResult.error(ErrorCodeEnum.ARGUMENT_NULL_EXIST);
}
// 这里非常非常重要 ... ...
// 仅当参数为MyRelationParam.full()的时候才会组装RelationManyToMany标注的关联。
sysRole = sysRoleService.getByIdWithRelation(roleId, MyRelationParam.full());
if (sysRole == null) {
return ResponseResult.error(ErrorCodeEnum.DATA_NOT_EXIST);
}
return ResponseResult.success(sysRoleDto);
}RelationOneToManyAggregation
一对多从表聚合计算数据关联。标记于主表实体对象的「计算结果」字段上,该字段必须同时被 @TableField(exist = false) 注解标记。如下面代码中的 totalSectionCount (课程总章节数量) 字段,由于该注解参数较多,因此每个参数的说明,已在下面的代码注释中给出,请务必仔细阅读并完全理解代码中的注释部分。
下面代码的业务场景是,一节课程对应多个课程章节,所以课程表 zz_course 和课程章节表 zz_course_section 之间是典型的「一对多」关系。每个课程章节都有课时数量字段,课程表没有总课时数量字段。如果希望在课程列表中显示总课时数,我们的计算方式是,累计当前课程中每一章节的课时数量,计算结果为该课程的总课时数。通过下面的注解代码,可以轻松实现这一关联和聚合计算的过程,至于性能问题,我们会在后面的章节中给出原理性分析。
@Data
@TableName(value = "zz_course")
public class Course {
// 主键Id。
@TableId(value = "course_id")
private Long courseId;
// 这里为了节省篇幅,省去若干字段 ... ...
// 这里需要特别强调的,和其他注解一样,该注解也支持远程服务数据聚合计算。
// 注解的 "slaveClientClass" 参数,其含义和RelationOneToOne中的完全一致。
// 课程总课时数量 (一对多聚合计算字段)。
@RelationOneToManyAggregation(
masterIdField = "courseId", // 指定当前类的courseId字段作为关联字段。
slaveServiceName = "sectionService", // 通过sectionService的接口获取课程章节的数据。
slaveModelClass = CourseSection.class, // 课程章节实体对象。
slaveIdField = "courseId", // 从表中CourseSection中的关联字段。
aggregationType = AggregationType.SUM, // 对从表"classHour"字段执行SUM计算。
aggregationField = "classHour") // 对从表的"classHour"字段执行聚合计算。
@TableField(exist = false)
private Integer totalClassHours = 0;
}
@Data
@TableName(value = "zz_course_section")
public class CourseSection {
// 主键Id。
@TableId(value = "section_id")
private Long sectionId;
// 课程Id。
@TableField(value = "course_id")
private Long courseId;
// 这里为了节省篇幅,省去若干字段 ... ...
// 章节课时数量。
// 就是该字段的数值累计相加后,得出所属课程的总课时数。
@TableField(value = "class_hour")
private Integer classHour;
}下面我们假设 zz_course_section 表中存在七条数据,分别属于下面的三门课程,见下表。
| section_id | course_id | ... ... | class_hour |
|---|---|---|---|
| 1 | 1000 | ... ... | 20 |
| 2 | 1000 | ... ... | 30 |
| 3 | 1001 | ... ... | 40 |
| 4 | 1001 | ... ... | 50 |
| 5 | 1002 | ... ... | 40 |
| 6 | 1002 | ... ... | 50 |
| 7 | 1002 | ... ... | 60 |
下面我们假设 zz_course 表中存在三门课程,见下表。
| course_id | course_name | ... ... |
|---|---|---|
| 1000 | 高一数学 | ... ... |
| 1001 | 高二数学 | ... ... |
| 1002 | 高一语文 | ... ... |
获取数据库结果集,并在后台服务程序的内存中,通过 Java 代码将实体对象与从表聚合计算后结果数据进行关联,其中从表数据采用 IN LIST 方式一次性计算和读取,因此性能更高。下面关联后的 JSON 格式数据和关键注释如下。
[
{
courseId: 1000,
courseName: "高一数学",
totalClassHours: 50
},
{
courseId: 1001,
courseName: "高二数学",
totalClassHours: 90
},
{
courseId: 1002,
courseName: "高一语文",
totalClassHours: 150
}
]RelationManyToManyAggregation
多对多从表聚合计算数据关联。标记于主表实体对象的「计算结果」字段上,该字段必须同时被 @TableField(exist = false) 注解标记。如下面代码中的 studentCount (班级学生数量) 和 classHour (班级课程总课时) 字段,由于该注解参数较多,因此每个参数的说明,已在下面的代码注释中给出,请务必仔细阅读并完全理解代码中的注释部分。
注解参数中的中间表必须和主表在同一个服务的同一个数据库链接中。
下面代码的业务场景是,一个学生可以参加多个培训班,所以班级和学生之间是「多对多」关系,同一套课程可以开在多个班,所以班级和课程也是典型的「多对多」关系。如果希望在班级列表中显示班级学生数量和班级课时总数,我们则需要进行如下的两步聚合计算。
- 显示班级学生数量。主表班级表 (zz_class) --> 中间表 (zz_class_student) --> 从表学生表 (zz_student)。由于仅仅需要计算学生的数量,因此无需关联从表,根据主表主键 classId,获取中间表中该主键所对应的记录数量即可。因为减少了对从表的关联,整个数据组装过程的性能得到了进一步提升。
- 显示班级课时总数。主表班级表 (zz_class) --> 中间表 (zz_class_course) --> 从表课程表 (zz_course)。这里先假设课程表中包含课时数量字段。由于需要累加课程表中的课时数字段 (classHour),因此从表将会参与整个关联和聚合计算的全过程。我们根据主表主键 ID,通过中间表关联实现从表数据的聚合计算。
@Data
@TableName(value = "zz_class")
public class StudentClass {
// 班级Id。
@TableId(value = "class_id")
private Long classId;
// 这里为了节省篇幅,省去若干字段 ... ...
// 请留意,studentCount的组装过程,是在服务内计算完成的。
// 班级学生数量 (多对多聚合计算字段)。
@RelationManyToManyAggregation(
masterIdField = "classId", // 指定当前类的classId字段作为关联字段。
slaveServiceName = "studentService", // 通过studentService获取计算结果。
relationModelClass = ClassStudent.class, // 中间表对象。
relationMasterIdField = "classId", // 中间表字段,用于和主表字段建立关联。
relationSlaveIdField = "studentId", // 中间表字段,用于和从表字段建立关联。
slaveModelClass = Student.class, // 从表对象。
slaveIdField = "studentId", // 从表字段,用于和中间表中从表关联字段关联。
aggregationModelClass = ClassStudent.class,// 聚合计算对象,这里是中间表。
aggregationType = AggregationType.COUNT, // 聚合计算函数。
aggregationField = "studentId") // 聚合计算对象中计算字段。
@TableField(exist = false)
private Integer studentCount = 0;
// 请留意,totalClassHour的组装过程,是跨服务计算完成的。
// 总课时数 (多对多聚合计算字段)。
@RelationManyToManyAggregation(
masterIdField = "classId", // 指定当前类的classId字段作为关联字段。
slaveClientClass = CourseClient.class, // 通过FeignClient服务间调用接口获取计算结果。
relationModelClass = ClassCourse.class, // 中间表对象。
relationMasterIdField = "classId", // 中间表字段,用于和主表字段建立关联。
relationSlaveIdField = "courseId", // 中间表字段,用于和从表字段建立关联。
slaveModelClass = CourseDto.class, // 因为是远程调用,所以是从表Dto对象。
slaveIdField = "courseId", // 从表字段,用于和中间表中从表关联字段关联。
aggregationModelClass = CourseDto.class, // 聚合计算对象,这里是从表。
aggregationType = AggregationType.SUM, // 聚合计算函数。
aggregationField = "classHour") // 聚合计算对象中计算字段。
@TableField(exist = false)
private Integer totalClassHour = 0;
}
/**
* 班级学生中间表。
*/
@Data
@TableName(value = "zz_class_student")
public class ClassStudent {
// 班级Id。
@TableField(value = "class_id")
private Long classId;
// 学生Id。
@TableField(value = "student_id")
private Long studentId;
}
/**
* 班级课程中间表。
*/
@Data
@TableName(value = "zz_class_course")
public class ClassCourse {
// 班级Id。
@TableField(value = "class_id")
private Long classId;
// 课程Id。
@TableField(value = "course_id")
private Long courseId;
}
/**
* 课程表(从表)
*/
@Data
@TableName(value = "zz_course")
public class Course {
// 主键Id。
@TableId(value = "course_id")
private Long courseId;
// 这里为了节省篇幅,省去若干字段 ... ...
// 课时数量。参与SUM计算的聚合字段。
@TableField(value = "class_hour")
private Integer classHour;
}下面是班级学生中间表的数据。
| class_id | student_id |
|---|---|
| 1000 | 100 |
| 1001 | 101 |
| 1001 | 102 |
| 1002 | 103 |
| 1002 | 103 |
| 1002 | 101 |
下面是班级课程中间表的数据。
| class_id | course_id |
|---|---|
| 1000 | 100 |
| 1001 | 101 |
| 1001 | 102 |
| 1002 | 103 |
| 1002 | 104 |
| 1002 | 105 |
下面是课程表中的数据。
| course_id | ... ... | class_hour |
|---|---|---|
| 100 | ... ... | 20 |
| 101 | ... ... | 30 |
| 102 | ... ... | 40 |
| 103 | ... ... | 50 |
| 104 | ... ... | 40 |
| 105 | ... ... | 50 |
下面我们假设 zz_class 表中存在三个班级,见下表。
| class_id | class_name | ... ... | student_count | total_class_hour |
|---|---|---|---|---|
| 1000 | 高一数学培优班 | ... ... | 2 | 20 |
| 1001 | 高二数学培优班 | ... ... | 1 | 70 |
| 1002 | 高一语文突击班 | ... ... | 3 | 140 |
NoAuthInterface
该注解仅用于单体工程,且仅能用于 Controller 类或类中的某个接口方法。如果注解标记于 Controller 类,那么该类的所有接口都是无需验证的,如标记于方法,只有被标记的接口是免验证的。这里的免验证是指,请求中无需携带 Token 仍可访问,如登录接口、通用字典白名单接口等。
@RestController
@RequestMapping("/admin/login")
public class LoginController {
@NoAuthInterface
@GetMapping("/doLogin")
public ResponseResult<?> doLogin(
@RequestParam String loginName, @RequestParam String password) {
// 忽略其中代码细节 ... ...
}
}DisableDataFilter
作为 DisableDataFilterAspect 的切点,标记于 Controller/Service 方法。在被标记方法内执行的 SQL 语句,均不会被 Mybatis 插件拦截并织入数据过滤相关的条件,如数据权限过滤。需要注意的是,该注解仅能标记于 Bean 中的方法,一定不要标记在 Bean 对象父类的方法上。请仔细阅读下面的代码及其注释。
@Service
public class CourseService extends BaseService {
// 由于CourseService是bean对象,因此该注解可以标注于他的方法。
@DisableDataFilter
public void getCourseList() {
// 忽略代码实现。
}
}
public class BaseService {
// 由于BaseService是bean对象CourseService的父类,
// 下面的注解是"不会"生效的。
@DisableDataFilter
public void oneMethod() {
// 忽略代码实现。
}
}EnableDataPerm
是否启用数据权限,应用于 Dao 层的 Mapper 类。一旦 Mapper 被标记该注解,Mapper 内所有未被排除的 SELECT 方法,均会经过数据权限的过滤,后面会有专门的章节详细介绍数据权限。见如下代码,CourseMapper 中除 getCourseList 之外的所有 SELECT 调用,都会被拦截并插入数据过滤条件。
@EnableDataPerm(excluseMethodName = {"getCourseList"})
public interface CourseMapper extends BaseDaoMapper<Course> {
<M> List<Course> getCourseList(
@Param("inFilterColumn") String inFilterColumn,
@Param("inFilterValues") Set<M> inFilterValues,
@Param("courseFilter") Course courseFilter,
@Param("orderBy") String orderBy);
<M> Integer getCourseCount(
@Param("inFilterColumn") String inFilterColumn,
@Param("inFilterValues") Set<M> inFilterValues,
@Param("courseFilter") Course courseFilter);
<M> List<Course> getNotInCourseList(
@Param("inFilterColumn") String inFilterColumn,
@Param("notInFilterValues") Set<M> notInFilterValues,
@Param("courseFilter") Course courseFilter,
@Param("orderBy") String orderBy);
}DisableTenantFilter
标记于 Dao 层的 Java Mapper 对象之上。该注解包含 includeMethodName 数组参数,数组中指定的 mapper 方法,均不会参与租户 ID 的过滤,见下面的代码及其注释。
// getSysDataPermListByUserId方法,因为包含在includeMethodName数组中,因此他被调用的时候,
// Mybatis拦截器不会将和租户Id过滤相关的条件,添加到该SQL的where从句中,而getSysDataPermList方法,
// 因为没有在排除的数组中,因为会被Mybatis拦截器自动添加与租户相关的where从句。
@DisableTenantFilter(includeMethodName = {"getSysDataPermListByUserId"})
public interface SysDataPermMapper extends BaseDaoMapper<SysDataPerm> {
// 获取数据权限列表。
List<SysDataPerm> getSysDataPermList(@Param("sysDataPermFilter") SysDataPerm sysDataPermFilter);
// 获取指定用户的数据权限列表。
List<SysDataPerm> getSysDataPermListByUserId(@Param("userId") Long userId);
}
// 在实体对象的声明代码中,tenantId字段被标记与tenantId字段,因此,以该实体对象作为主表的查询,
// 会被Mybatis拦截器自动添加where条件,如: AND tenant_id = 123。
@Data
@EqualsAndHashCode(callSuper = true)
@TableName(value = "zz_sys_data_perm")
public class SysDataPerm extends BaseModel {
// 主键Id。
@TableId(value = "data_perm_id")
private Long dataPermId;
// 租户Id。
@TenantFilterColumn
@TableField(value = "tenant_id")
private Long tenantId;
// 其余字段声明忽略 ... ...
}TenantFilterColumn
租户 ID 过滤注解。标记于实体对象字段之上,在所有以该实体对象为主表的 SELECT/UPDATE/DELETE 等 SQL 语句,都会被 Mybatis 拦截器自动添加 WHERE 过滤条件,如:AND tenant_id = 123。需要说明的是,和数据权限过滤注解一样,在服务启动的监听器中,会加载所有与该注解相关的信息,以保证在服务运行时可以快速读取,从而提升系统执行效率。
@Data
@EqualsAndHashCode(callSuper = true)
@TableName(value = "zz_sys_data_perm")
public class SysDataPerm extends BaseModel {
// 主键Id。
@TableId(value = "data_perm_id")
private Long dataPermId;
// 租户Id。
@TenantFilterColumn
@TableField(value = "tenant_id")
private Long tenantId;
// 其余字段声明忽略 ... ...
}DeptFilterColumn
数据权限中使用的部门级数据过滤字段。
@Data
@TableName(value = "zz_course")
public class Course {
// 主键Id。
@TableId(value = "course_id")
private Long courseId;
// 中间忽略若干字段 ... ...
// 所属校区。
@DeptFilterColumn
@TableField(value = "school_id")
private Long schoolId;
}我们假设数据权限过滤规则为「只看本部门」。由于 school_id 字段被标记为部门级数据过滤字段,因此下面的 SQL 语句会被添加 school_id = #{deptId} 的过滤条件
-- 数据权限拦截并注入前
SELECT * FROM zz_course WHERE course_name LIKE '%中学%'
-- 数据权限拦截并注入后
SELECT * FROM zz_course WHERE course_name LIKE '%中学%' AND school_id = 1UserFilterColumn
数据权限中使用的用户级数据过滤字段。
@Data
@TableName(value = "zz_class")
public class StudentClass {
// 班级Id。
@TableId(value = "class_id")
private Long classId;
// 中间忽略若干字段 ... ...
// 创建用户。
@UserFilterColumn
@TableField(value = "create_user_id")
private Long createUserId;
}我们假设数据权限过滤规则为「只看自己」。由于 create_user_id 字段被标记为用户级数据过滤字段,因此下面的 SQL 语句会被添加 create_user_id = #{userId} 的过滤条件。
-- 数据权限拦截并注入前
SELECT * FROM zz_class WHERE class_name LIKE '%中学%'
-- 数据权限拦截并注入后
SELECT * FROM zz_class WHERE class_name LIKE '%中学%' AND create_user_id = 2MyDataSource
仅应用于多数据源场景,标记于 Service 实现类,注解参数指定了应使用的目标数据源类型。注解的拦截和多数据源的切换,均在 AOP 类 DataSourceAspect 中统一实现。
// DataSourceType.TRANS,类型参数指示从流水(Trans)数据源中获取年级数据。
@MyDataSource(DataSourceType.TRANS)
@Service
public class GradeService extends BaseJobService<Grade, Integer> {
@Autowired
private GradeMapper gradeMapper;
// 返回当前Service的主表Mapper对象。
@Override
protected BaseJobMapper<Grade> mapper() {
return gradeMapper;
}
}DataSourceType 的常量值与多数据源之间的对应关系,是在系统启动时自动加载的,而对于单数据源的服务模块,MultiDataSourceConfig.java 和 DataSourceType.java 文件均不存在。见如下代码。
@Configuration
@EnableTransactionManagement
public class MultiDataSourceConfig {
... ...
@Bean
@Primary
public DynamicDataSource dataSource() {
Map<Object, Object> targetDataSources = new HashMap<>(2);
targetDataSources.put(DataSourceType.UPMS, upmsDataSource());
targetDataSources.put(DataSourceType.TRANS, transDataSource());
targetDataSources.put(DataSourceType.STATS, statsDataSource());
DynamicDataSource dynamicDataSource = new DynamicDataSource();
dynamicDataSource.setTargetDataSources(targetDataSources);
dynamicDataSource.setDefaultTargetDataSource(upmsDataSource());
return dynamicDataSource;
}
}MyDataSourceResolver
仅应用于多数据源场景,标记于 Service 实现类。通过自定义的解析规则,选择目标数据源。该注解定义如下。
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface MyDataSourceResolver {
// 多数据源路由键解析接口的Class。
Class<? extends DataSourceResolver> resolver();
// DataSourceResolver.resovle方法的入参。
String arg() default "";
}通过上面的代码可以看出,在实际开发中,我们需要实现 DataSourceResolver 接口,并在接口实现类中实现数据源路由的动态解析逻辑。下面为接口定义。
public interface DataSourceResolver {
// 动态解析方法。实现类可以根据当前的请求,或者上下文环境进行动态解析。
// 可选的入参,为MyDataSourceResolver注解中的arg参数。
// 返回用于多数据源切换的类型值。DataSourceResolveAspect 切面方法会根据配置信息,进行多数据源切换。
int resolve(String arg);
}注解的拦截和多数据源的切换,均在 AOP 类 DataSourceResolveAspect 中统一实现。下面为该注解标注于 Service 实现类的示例代码,更多具体示例可参考 [架构进阶必读章节的多数据源解析器小节](../advance/#多数据源解析器)。
// ChannelDataSourceResolver类实现了该接口,具体实现可参考进阶必读的多数据源章节。
@MyDataSourceResolver(resolver = ChannelDataSourceResolver.class)
@Service("courseService")
public class CourseServiceImpl extends BaseService<Course, Long> implements CourseService {
// 这里忽略业务代码的实现。
}MyRequestBody
用于标记 Controller 的接口参数。该注解的解析是在 MyRequestArgumentResolver 请求参数解析器对象中实现的。目前仅支持 POST 请求,请求消息体内容必须为 JSON 格式。具体的应用场景,请参考本章节的「参数解析」小节,
@Slf4j
@RestController
@RequestMapping("/studentActionStats")
public class StudentActionStatsController {
// Http请求的JSON数据格式为:
// {
// studentActionStatsFilter: {gradeId: 2, statsMonth: "202003"},
// orderParam: {fieldName: "statsDate", asc: true},
// pageParam: {pageNum: 0, pageSize: 10}
// }
// MyRequestArgumentResolver参数解析器对象,基于JSON键名称与接口参数名的一一
// 对应关系,通过反射的方式进行数据对象赋值。结果为:
//
// studentActionStatsFilter.gradeId = 2
// studentActionStatsFilter.statsMonth = "202003"
// orderParam.fieldName = "statsDate"
// orderParam.asc = true
// pageParam.pageNum = 0
// pageParam.pageSize = 10
@PostMapping("/list")
public ResponseResult<?> list(
@MyRequestBody StudentActionStats studentActionStatsFilter,
@MyRequestBody MyOrderParam orderParam,
@MyRequestBody MyPageParam pageParam) {
// 具体实现代码忽略 ... ...
}
} OperationLog
主要标记于 Controller 对象中的接口方法,被该注解标记的方法,在被请求调用时均会产生操作日志,并缺省存入操作日志表所在的数据库中。微服务工程的业务微服务,会将操作日志发送给 Kafka,再由独立的消费者服务进行统一处理,我们默认的处理方式是存储到独立的 MySQL 操作日志数据库中,但是开发者可以根据实际情况将其存入其他数据源,如 ElasticSearch 等。更多详情可参考开发文档的 操作日志章节。
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface OperationLog {
// 描述。
String description() default "";
// 操作类型。
int type() default SysOperationLogType.OTHER;
// 是否保存应答结果。
// 对于类似导出和文件下载之类的接口,该参与应该设置为false。
boolean saveResponse() default true;
}监听器
在橙单生成的工程中,为了提升应用服务的整体运行时效率,我们提供了以下监听器类,用于在服务启动时,预先加载并计算出运行时所需的数据结构。
- LoadServiceRelationListener
- LoadDataFilterInfoListener
LoadServiceRelationListener
在业务服务启动时,将用于多表间数据组装的注解提前解析,并在内存中完成数据结构的搭建,如 @RelationGlobalDict、@RelationOneToOne 等,
@Component
public class LoadServiceRelationListener implements ApplicationListener<ApplicationReadyEvent> {
@Override
public void onApplicationEvent(ApplicationReadyEvent applicationReadyEvent) {
Map<String, BaseService> serviceMap =
applicationReadyEvent.getApplicationContext().getBeansOfType(BaseService.class);
for (Map.Entry<String, BaseService> e : serviceMap.entrySet()) {
e.getValue().loadLocalRelationStruct();
e.getValue().loadRemoteRelationStruct();
}
}
}在如上代码中,监听器会加载所有类型为 BaseService 的 Bean 对象,同时迭代并执行 loadLocalRelationStruct 和 loadRemoteRelationStruct 方法。其中前者加载服务内的数据关联,而后者加载微服务间的数据关联。下面我们仅给出 loadLocalRelationStruct 方法的部分实现,而有关数据组装的更多细节可参考本章前面的内容。
public void loadLocalRelationStruct() {
Field[] fields = ReflectUtil.getFields(modelClass);
for (Field f : fields) {
RelationDict relationDict = f.getAnnotation(RelationDict.class);
if (relationDict != null) {
if (localRelationDictStructList == null) {
localRelationDictStructList = new LinkedList<>();
}
LocalRelationStruct relationStruct = new LocalRelationStruct();
relationStruct.relationField = f;
relationStruct.masterIdField =
ReflectUtil.getField(modelClass, relationDict.masterIdField());
relationStruct.relationDict = relationDict;
relationStruct.localService = ApplicationContextHolder.getBean(
StringUtils.uncapitalize(relationDict.slaveServiceName()));
localRelationDictStructList.add(relationStruct);
continue;
}
// 下面忽略其他数据关联注解的解析。
}
}从上面的代码中,我们可以看到预加载方法完成了大量的反射解析工作,并将反射元对象保存到内存中,以便运行时直接使用,从而可大幅提升服务的运行时效率。
LoadDataFilterInfoListener
业务服务启动时,将扫描所有用于数据过滤的注解 @EnableDataPerm、@DeptFilterColumn、@UserFilterColumn 和 @TenantFilterColumn,并在内存中完成数据结构的搭建。
@Component
public class LoadDataFilterInfoListener implements ApplicationListener<ApplicationReadyEvent> {
@Override
public void onApplicationEvent(ApplicationReadyEvent applicationReadyEvent) {
MybatisDataFilterInterceptor interceptor =
applicationReadyEvent.getApplicationContext().getBean(MybatisDataFilterInterceptor.class);
interceptor.loadInfoWithDataFilter();
}
}在如上代码中,监听器获取 MybatisDataFilterInterceptor 拦截器对象,并调用该对象的 loadInfoWithDataFilter 方法,预先加载服务运行时所需的数据过滤对象信息,其具体价值如下。
- 数据权限过滤和租户数据过滤,均为被高频调用的计算过程。
- 解析过程中,会存在大量的反射代码,因此效率相对较低,预解析后可以显著提升计算过程的运行时效率。
// 这里仅给出少部分的代码实现,作为示意,更多细节可自行参考源码。
@Component
public class MybatisDataFilterInterceptor implements Interceptor {
public void loadInfoWithDataFilter() {
// 1. 这里获取了所有类型为Mapper的bean对象。
Map<String, BaseDaoMapper> mapperMap =
ApplicationContextHolder.getApplicationContext().getBeansOfType(BaseDaoMapper.class);
for (BaseDaoMapper<?> mapperProxy : mapperMap.values()) {
// 优先处理jdk的代理
Object proxy = ReflectUtil.getFieldValue(mapperProxy, "h");
// 如果不是jdk的代理,再看看cjlib的代理。
if (proxy == null) {
proxy = ReflectUtil.getFieldValue(mapperProxy, "CGLIB$CALLBACK_0");
}
Class<?> mapperClass =
(Class<?>) ReflectUtil.getFieldValue(proxy, "mapperInterface");
// 如果配置中打开的租户过滤的开关,这里会加载与租户Id过滤相关的数据。
if (properties.getEnabledTenantFilter()) {
loadTenantFilterData(mapperClass);
}
// 如果配置中打开的数据权限过滤的开关,这里会加载数据权限过滤相关的数据。
if (properties.getEnabledDataPermFilter()) {
EnableDataPerm rule = mapperClass.getAnnotation(EnableDataPerm.class);
if (rule != null) {
loadDataPermFilterRules(mapperClass, rule);
}
}
}
}
}配置类
本小节主要介绍橙单基础框架中,与配置相关的类对象。
CorsConfig
跨域信任配置对象,对于前后端分离的工程而言,这是必须配置的,因为前端工程和后台接口服务位于不同的域内。
- 微服务工程中,该配置类位于网关服务的 config 包内,所有的跨域信任处理都交由网关统一完成。
- 单体工程中,位于业务服务 config 包内的 FilterConfig 配置类内。
// 单体和微服务工程的此段代码实现逻辑几乎相同,这里我们仅给出单体服务的实现。
@Configuration
public class FilterConfig {
@Bean
public CorsFilter corsFilterRegistration(ApplicationConfig applicationConfig) {
UrlBasedCorsConfigurationSource configSource = new UrlBasedCorsConfigurationSource();
CorsConfiguration corsConfiguration = new CorsConfiguration();
if (StringUtils.isNotBlank(applicationConfig.getCredentialIpList())) {
if ("*".equals(applicationConfig.getCredentialIpList())) {
corsConfiguration.addAllowedOriginPattern("*");
} else {
String[] credentialIpList = StringUtils.split(applicationConfig.getCredentialIpList(), ",");
if (credentialIpList.length > 0) {
for (String ip : credentialIpList) {
corsConfiguration.addAllowedOrigin(ip);
}
}
}
corsConfiguration.addAllowedHeader("*");
corsConfiguration.addAllowedMethod("*");
corsConfiguration.addExposedHeader(applicationConfig.getRefreshedTokenHeaderKey());
corsConfiguration.setAllowCredentials(true);
configSource.registerCorsConfiguration("/**", corsConfiguration);
}
return new CorsFilter(configSource);
}
// ... ... 省略部分其他不相干代码。
}FeignConfig
该配置对象仅微服务工程可用。可以保证在跨服务调用时,将当前服务的 Token 信息以及请求中的 traceId 存放到 HTTP Head 中,并传递给被调用的服务,以便被调用服务可以正常得到本次请求的用户身份信息,同时在记录日志时,整个链路都可以使用统一的 traceId。
@Configuration
public class FeignConfig implements RequestInterceptor {
@SneakyThrows
@Override
public void apply(RequestTemplate requestTemplate) {
// 对于非servlet请求发起的远程调用,由于无法获取到标识用户身份的TokenData,因此需要略过下面的HEADER注入。
// 如:由消息队列consumer发起的远程调用请求。
if (!ContextUtil.hasRequestContext()) {
return;
}
String tokenData = ContextUtil.getHttpRequest().getHeader(TokenData.REQUEST_ATTRIBUTE_NAME);
if (StrUtil.isBlank(tokenData)) {
JSONObject token = (JSONObject)
ContextUtil.getHttpRequest().getAttribute(TokenData.REQUEST_ATTRIBUTE_NAME);
if (token != null) {
tokenData = token.toJSONString();
}
}
if (StrUtil.isNotBlank(tokenData)) {
requestTemplate.header(TokenData.REQUEST_ATTRIBUTE_NAME, tokenData);
}
String traceId = ContextUtil.getHttpRequest().getHeader(ApplicationConstant.HTTP_HEADER_TRACE_ID);
if (StrUtil.isBlank(traceId)) {
traceId = (String)
ContextUtil.getHttpRequest().getAttribute(ApplicationConstant.HTTP_HEADER_TRACE_ID);
}
if (StrUtil.isNotBlank(traceId)) {
requestTemplate.header(ApplicationConstant.HTTP_HEADER_TRACE_ID, traceId);
}
}
}TomcatConfig
这个配置是和安全扫描有关的,有些金融企业要求禁用危险性较高的 HTTP Method。
@Configuration
public class TomcatConfig {
@Bean
public TomcatServletWebServerFactory servletContainer() {
TomcatServletWebServerFactory factory = new TomcatServletWebServerFactory();
factory.addContextCustomizers(context -> {
SecurityConstraint securityConstraint = new SecurityConstraint();
securityConstraint.setUserConstraint("CONFIDENTIAL");
SecurityCollection collection = new SecurityCollection();
collection.addPattern("/*");
collection.addMethod("HEAD");
collection.addMethod("PUT");
collection.addMethod("PATCH");
collection.addMethod("DELETE");
collection.addMethod("TRACE");
collection.addMethod("COPY");
collection.addMethod("SEARCH");
collection.addMethod("PROPFIND");
securityConstraint.addCollection(collection);
context.addConstraint(securityConstraint);
});
return factory;
}
}CacheConfig
一级缓存配置。目前仅提供了集成 Caffeine 开源库的一级缓存功能。对于调用高频的「用户权限验证」和「数据权限过滤」等功能,都在原有二级缓存 (Redis) 的基础上增设了一级缓存,以进一步提升系统的运行时效率。
@Configuration
@EnableCaching
public class CacheConfig {
private static final int DEFAULT_MAXSIZE = 10000;
private static final int DEFAULT_TTL = 3600;
// 定义cache名称、超时时长秒、最大个数
// 每个cache缺省3600秒过期,最大个数1000
public enum CacheEnum {
// 专门存储用户权限的缓存。
UserPermissionCache(1800),
// 专门存储用户数据权限的缓存。
DataPermissionCache(7200),
// 缺省全局缓存(时间是24小时)。
GlobalCache(86400,20000);
CacheEnum() {
}
CacheEnum(int ttl) {
this.ttl = ttl;
}
CacheEnum(int ttl, int maxSize) {
this.ttl = ttl;
this.maxSize = maxSize;
}
// 缓存的最大数量。
private int maxSize = DEFAULT_MAXSIZE;
// 缓存的时长(单位:秒)
private int ttl = DEFAULT_TTL;
}
@Bean
public CacheManager cacheManager() {
SimpleCacheManager manager = new SimpleCacheManager();
//把各个cache注册到cacheManager中,
// CaffeineCache实现了org.springframework.cache.Cache接口
ArrayList<CaffeineCache> caches = new ArrayList<>();
for (CacheEnum c : CacheEnum.values()) {
caches.add(new CaffeineCache(c.name(),
Caffeine.newBuilder().recordStats()
.expireAfterAccess(c.getTtl(), TimeUnit.SECONDS)
.maximumSize(c.getMaxSize())
.build())
);
}
manager.setCaches(caches);
return manager;
}
}CommonWebMvcConfig
这里主要配置应用服务所需的拦截器、Controller 接口参数解析器,以及应答消息的转换器。
@Configuration
public class CommonWebMvcConfig implements WebMvcConfigurer {
@Override
public void addArgumentResolvers(
List<HandlerMethodArgumentResolver> argumentResolvers) {
// 添加MyRequestBody参数解析器
argumentResolvers.add(new MyRequestArgumentResolver());
}
private HttpMessageConverter<String> responseBodyConverter() {
return new StringHttpMessageConverter(StandardCharsets.UTF_8);
}
private FastJsonHttpMessageConverter fastJsonHttpMessageConverters() {
FastJsonHttpMessageConverter fastConverter =
new FastJsonHttpMessageConverter();
List<MediaType> supportedMediaTypes = new ArrayList<>();
supportedMediaTypes.add(MediaType.APPLICATION_JSON);
supportedMediaTypes.add(MediaType.APPLICATION_FORM_URLENCODED);
fastConverter.setSupportedMediaTypes(supportedMediaTypes);
FastJsonConfig fastJsonConfig = new FastJsonConfig();
fastJsonConfig.setSerializerFeatures(
SerializerFeature.PrettyFormat,
SerializerFeature.DisableCircularReferenceDetect,
SerializerFeature.IgnoreNonFieldGetter);
fastJsonConfig.setDateFormat("yyyy-MM-dd HH:mm:ss");
fastConverter.setFastJsonConfig(fastJsonConfig);
return fastConverter;
}
// 这里主要是配置应答数据对象的字符编码,保证中文数据可以正常显示。目前我们都使用UTF-8。
@Override
public void configureMessageConverters(List<HttpMessageConverter<?>> converters) {
converters.add(responseBodyConverter());
converters.add(new ByteArrayHttpMessageConverter());
converters.add(fastJsonHttpMessageConverters());
}
}拦截器
本小节主要介绍橙单基础框架中的拦截器对象。
DataFilterInterceptor
在调用 Controller 接口方法之前,强制将数据过滤标记设置为缺省值。
@Slf4j
public class DataFilterInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
throws Exception {
// 每次进入Controller接口之前,均主动打开数据权限验证。
// 可以避免该Servlet线程在处理之前的请求时异常退出,从而导致该状态数据没有被正常清除。
GlobalThreadLocal.setDataFilter(true);
return true;
}
@Override
public void afterCompletion(
HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex)
throws Exception {
GlobalThreadLocal.clearDataFilter();
}
}AuthenticationInterceptor
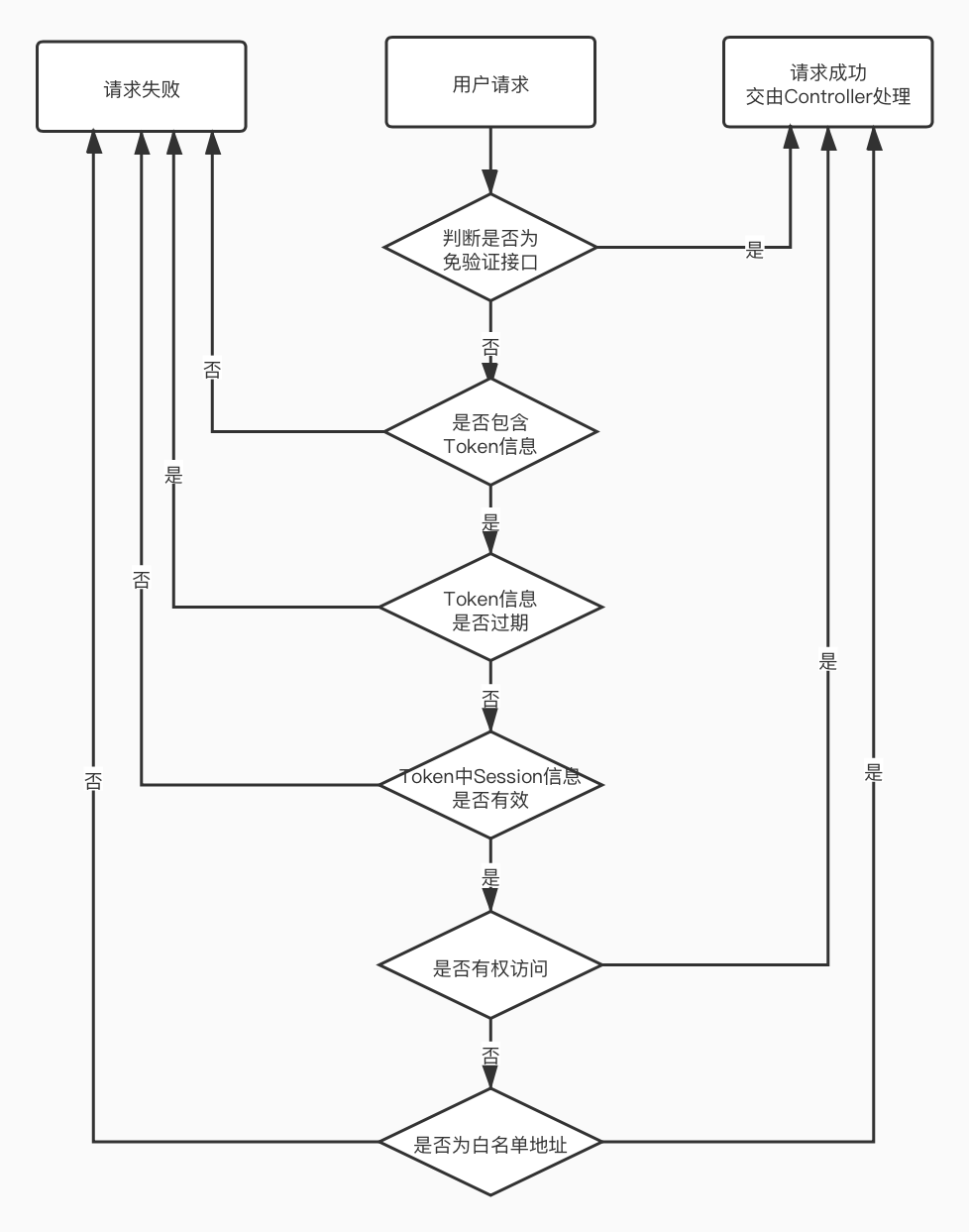
该拦截器仅应用于单体服务,对于微服务工程,用户权限统一验证的功能,是在网关前置过滤器中实现的。具体处理逻辑,请参考以下流程图。
AOP
本小节主要介绍橙单基础框架中的 AOP 对象。
OperationLogAspect
织入所有 Controller 接口方法,在接口方法被调用之前,将拦截并输出所有 HTTP 请求参数到日志系统,同时记录开始执行时间。在执行完接口方法后,将继续拦截并输出所有 HTTP 请求和应答数据,以及该 Controller 接口的执行时间。此外,对于添加 @OperationLog 注解的接口方法,还会将访问日志存入到操作日志表中 (zz_sys_operation_log),具体逻辑可参考开发文档的 操作日志章节。最后需要重点提及的是,单体服务的 traceId 是通过该 AOP 方法计算而得。微服务工程,则是由网关的 RequestLogFilter 过滤器统一生成,并通过 HTTP HEAD 传递给后续所有微服务。
- 在服务的配置文件中添加如下配置。
common-log:
# 操作日志配置,对应配置文件common-log/OperationLogProperties.java
operation-log:
enabled: true- 为 Controller 接口方法添加 @OperationLog 注解。
@OperationLog(type = SysOperationLogType.ADD)
@PostMapping("/add")
public ResponseResult<Integer> add(@MyRequestBody("grade") GradeDto gradeDto) {
// ... ... 省略接口方法实现代码,重点关注上面的@OperationLog注解。
}- 下面是 OperationLogAspect 切面类的代码实现,请仔细阅读代码中的关键性注释。
@Aspect
@Slf4j
public class OperationLogAspect {
// 所有controller方法。
@Pointcut("execution(public * com.demo.multi..controller..*(..))")
public void operationLogPointCut() {
// 空注释,避免sonar警告
}
@Around("operationLogPointCut()")
public Object around(ProceedingJoinPoint joinPoint) throws Throwable {
// 计时。
long start = System.currentTimeMillis();
HttpServletRequest request = ContextUtil.getHttpRequest();
HttpServletResponse response = ContextUtil.getHttpResponse();
// 对于微服务工程,该值已在网关服务的RequestLogFilter过滤器中计算而得。
// 这里可以直接取出,不用另行计算了。
String traceId = (String) request.getAttribute(ApplicationConstant.HTTP_HEADER_TRACE_ID);
// 对于单体工程,上一步获取的traceId为空值,并会在下面的代码中,为本次请求计算出唯一的traceId。
if (StringUtils.isBlank(traceId)) {
traceId = MyCommonUtil.generateUuid();
}
// 将流水号通过应答头返回给前端,便于问题精确定位。
response.setHeader(ApplicationConstant.HTTP_HEADER_TRACE_ID, traceId);
request.setAttribute(ApplicationConstant.HTTP_HEADER_TRACE_ID, traceId);
TokenData tokenData = TokenData.takeFromRequest();
// 为日志框架设定变量,使日志可以输出更多有价值的信息。
// MDC是日志框架内置的对象。
if (tokenData != null) {
MDC.put("sessionId", tokenData.getSessionId());
MDC.put("userId", tokenData.getUserId().toString());
}
MDC.put(ApplicationConstant.HTTP_HEADER_TRACE_ID, traceId);
// 获取本次请求的参数数据,以便于日志的统一保存。
String[] parameterNames = this.getParameterNames(joinPoint);
Object[] args = joinPoint.getArgs();
JSONObject jsonArgs = new JSONObject();
for (int i = 0; i < args.length; i++) {
Object arg = args[i];
if (this.isNormalArgs(arg)) {
String parameterName = parameterNames[i];
jsonArgs.put(parameterName, arg);
}
}
String params = jsonArgs.toJSONString();
SysOperationLog operationLog = null;
OperationLog operationLogAnnotation = null;
// 判断common-log.operation-log.enabled配置项是否打开。
boolean saveOperationLog = properties.isEnabled();
if (saveOperationLog) {
// 如果配置项已经打开,将继续判断当前controller接口,是否添加了OperationLog注解。
operationLogAnnotation = getOperationLogAnnotation(joinPoint);
saveOperationLog = (operationLogAnnotation != null);
}
if (saveOperationLog) {
// 构建保存到zz_sys_operation_log表中的数据对象。
operationLog = this.buildSysOperationLog(
operationLogAnnotation, joinPoint, params, traceId, tokenData);
}
Object result;
log.info("开始请求,url={}, reqData={}", request.getRequestURI(), params);
try {
// 调用Controller中的接口方法
result = joinPoint.proceed();
String respData = result == null ? "null" : JSON.toJSONString(result);
Long elapse = System.currentTimeMillis() - start;
// 对操作日志对象进行后处理,可以简单理解为补齐部分日志数据。
if (saveOperationLog) {
this.operationLogPostProcess(operationLogAnnotation, respData, operationLog, result);
}
if (elapse > properties.getSlowLogMs()) {
log.warn("耗时较长的请求完成警告, url={},elapse={}ms reqData={} respData={}",
request.getRequestURI(), elapse, params, respData);
}
log.info("请求完成, url={},elapse={}ms, respData={}", request.getRequestURI(), elapse, respData);
} catch (Exception e) {
log.error("请求报错,app={}, url={}, reqData={}, error={}",
applicationName, url, params, e.getMessage());
throw e;
} finally {
// 判断当前操作是否需要记录操作日志,如果需要则插入数据库操作日志表。
// 这里的代码是单体工程中的示例,对于微服务工程,则发送Kafka消息。并由专门的消费者
// 服务,负责将所有业务微服务收集的操作日志,集中插入到操作日志表所在的数据库中。
if (saveOperationLog) {
operationLog.setElapse(System.currentTimeMillis() - start);
operationLogService.saveNewAsync(operationLog);
}
// 清除存储在线程本地化中的日志变量。
MDC.remove(ApplicationConstant.HTTP_HEADER_TRACE_ID);
if (tokenData != null) {
MDC.remove("sessionId");
MDC.remove("userId");
}
}
return result;
}
}DisableDataFilterAspect
在 Controller / Service 类中,被添加 @DisableDataFilter 注解的方法,其方法内所有 SQL 请求均被禁用数据权限过滤。从该方法返回后,会自动恢复至之前的过滤标记状态。
@Aspect
@Component
@Order(1)
@Slf4j
public class DisableDataFilterAspect {
// 所有标记了DisableDataFilter注解的方法。
@Pointcut("@annotation(com.demo.multi.common.core.annotation.DisableDataFilter)")
public void disableDataFilterPointCut() {}
@Around("disableDataFilterPointCut()")
public Object around(ProceedingJoinPoint point) throws Throwable {
boolean dataFilterEnabled = GlobalThreadLocal.setDataFilter(false);
try {
return point.proceed();
} finally {
GlobalThreadLocal.setDataFilter(dataFilterEnabled);
}
}
}DataSourceAspect
多数据源切换 AOP。请参考 架构进阶必读章节的多数据源小节。
DataSourceResolverAspect
多数据源切换 AOP。请参考 架构进阶必读章节的多数据源解析器小节。
结语
赠人玫瑰,手有余香,感谢您的支持和关注,选择橙单,效率乘三,收入翻番。