前言
本栏目内容为橙单代码生成工具的在线帮助文档,可通过橙单工具中每个配置页面右上角的「帮助」按钮直接跳转。
字典类型比对
在开始介绍每个类型的字典之前,我们先看一下他们之间的差别,以便于在系统设计中,可以做出更为合适的选择。
| 数据表支持 | 单独数据表 | 字典对象 | 请求接口 | 通用性 | 运行效率 | 数据更新 | 字典缓存 | 树形结构 | |
|---|---|---|---|---|---|---|---|---|---|
| 常量字典 | 无 | 无 | 常量类 | 无 | 一般 | 最高 | 不支持 | 内存 | 不支持 |
| 全局编码字典 | 有 | 否 | 公用字典类 | 有 | 最高 | 高 | 支持 | Redis | 不支持 |
| 数据表字典 | 有 | 是 | 表实体对象 | 有 | 较高 | 低 | 支持 | 数据库 | 支持 |
| 字典表字典 | 有 | 是 | 表实体对象 | 有 | 一般 | 高 | 支持 | Redis | 支持 |
全局编码字典
在大多数业务系统中,全局编码字典的应用是最为广泛的。通常情况下,应该成为数据字典的首选类型。下面我们介绍一下该类型字典的配置和代码生成过程。
- 全局编码字典的「所属服务」配置项必须为 UPMS 服务,本小节后面会给出详细的代码截图和文字说明。

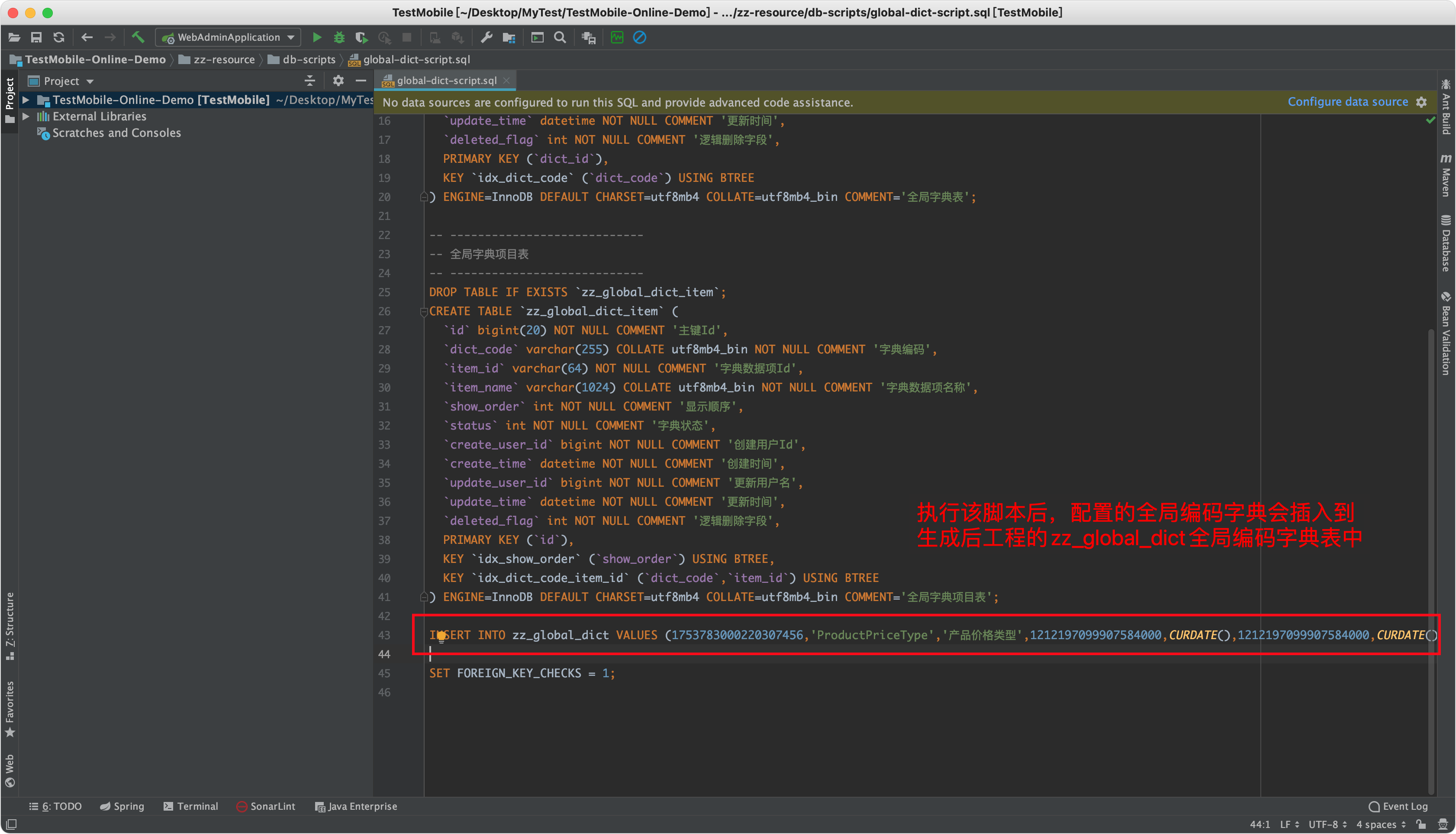
- 上图配置的全局编码字典,会出现在生成后工程的数据库脚本「global-dict-script.sql」文件中,如下图所示。
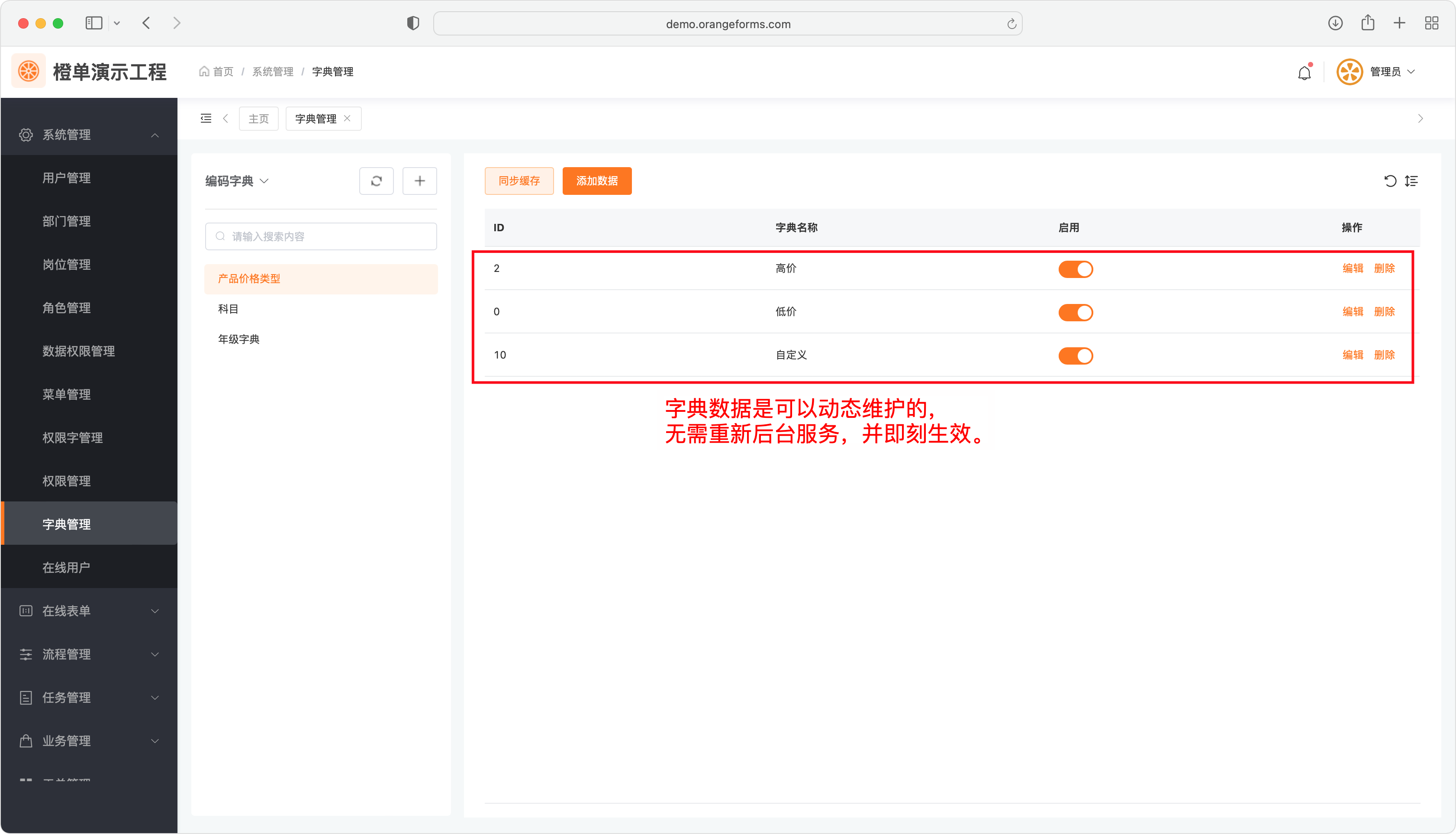
- 全局编码字典的数据项,仅能在生成后工程的「字典管理」中进行动态配置,并立即生效。
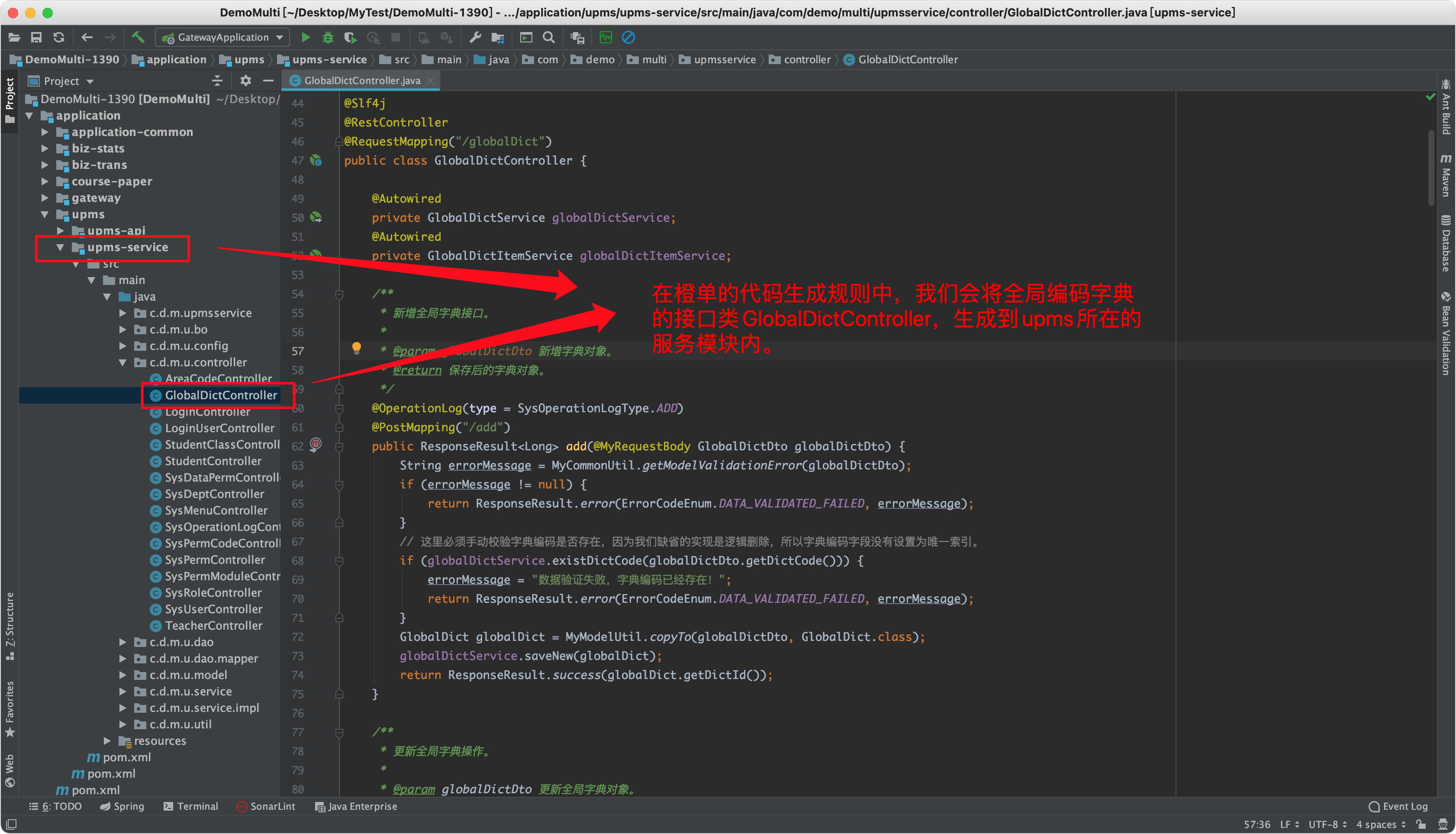
- 最后介绍一下为什么全局编码字典的「所属服务」必须为 UPMS。见下图中的文字说明。
常量字典
常量字典的定义会同时出现在前后端工程的代码中,且数据定义必须保持一致。
- 常量字典配置后,会在生成后的前后端工程中,分别存在与之对应的常量类。

- 上图配置的常量字典「所属服务」为业务通用模块,因此字典常量类会被生成到后台的 application-common 模块中,所有业务服务均可依赖引入并使用。如「所属服务」为业务服务模块,该常量类的代码则会被直接生成到指定的业务模块中,且仅该服务模块内可用。

- 常量字典的「字典标识」和「常量名前缀」配置项,对生成后代码的影响如下图所示。

数据源字典
数据源字典就是为业务表的 Controller 接口类增加了 listDict 的方法,使该表的数据可以被其他业务表以字典的形式进行关联使用,这将是极为灵活且规范的。相比于字典表字典和全局编码字典,数据源字典没有专门的字典数据维护页面,因为他的数据管理源于业务表页面的 「增删改」功能。下面我们将进一步介绍该类型字典的配置过程,以及生成后代码的详解。
- 由于数据源字典必须依赖已经配置的数据源接口,因此我们先简单介绍一下数据源的配置。更多细节可参考 数据源配置章节。
- 将已经导入到橙单的数据库表,导入到指定的服务。

- 继续为已导入到服务的数据表配置数据源。

- 基于上图配置的数据源「甲方公司」配置数据源字典。

- 最后给出数据源字典的生成后代码。如下图所示,我们为 Controller 类多生成了 listDict 和 listDictByIds 接口方法,并以字典数据的「键值对」形式返回列表数据。

字典表字典
字典表字典与数据源字典的配置完全一致,因此本小节不在做重复说明了。下面我们仅给出「字典表字典」和「数据源字典」之间的相同点和差别点,以供大家参考。
与数据源字典相比的相同点。
- 都必须依赖已经导入到服务的数据表,同时也必须配置数据源。
- 树形字典的配置方式也完全相同,既表字段中必须包含「父级主键」的字段属性,具体操作可参考本章后面 常问项配置的树形字典小节。
- 在生成后的 Controller 类中,同样会生成 listDict 和 listDictByIds 接口方法,数据返回格式也完全相同。
与数据源字典相比的差异点。
- 字典表结构通常只有 ID 和 NAME 两个字段,最多可能还会包含数据可用状态的字段,如下图所示的教材版本字典表「zz_material_edition」。

- 字典表字典的数据会被全部缓存,因此数据关联的运行时效率更高。
- 字典表字典的数据维护,存在专门的配置页面,具体可见下图。

常问配置项
以下均为在日常技术支持过程中经常会被问到的问题,为了尽可能的节省用户的时间,我们会根据用户的反馈,持续总结并完善该小节。
树形字典
仅当数据源所依赖的数据表支持「父级主键」时,当前数据源字典才会自动被视为树形字典。这里我们以内置的部门表「zz_sys_dept」为例,具体操作见以下截图及其文字说明。


结语
赠人玫瑰,手有余香,感谢您的支持和关注,选择橙单,效率乘三,收入翻番。