前言
本章以下小节主要介绍了数据字典的基础知识、代码生成和配置操作。
- 字典翻译解释。
- 业务场景。
- 字典类型比对。
- 常量字典。
- 全局编码字典。
- 字典表字典。
- 数据源字典。
最后几小节则主要介绍了橙单数据字典的代码实现细节和技术优势。
- 应用代码分析。
- 字典翻译的优势。
字典翻译
在开始阅读本章节的内容之前,我们需要先对齐一下「字典翻译」这个术语的含义。通常情况下,业务表字段中会包含字典数据的 ID 值,而前端页面则需要显示与之对应的 NAME 字段值。因此后台接口在返回数据前,会根据业务表字段中的字典 ID 值,逐一翻译成对应的字典 NAME 值,最后将翻译结果绑定到返回对象中,我们称该过程为「字典翻译」。
业务场景
这里我们根据自身的项目经验和用户反馈,列举一下数据字典的常用业务场景。
查询过滤下拉框
列表页面的过滤条件中,下拉框数据通常会来自于数据字典。

数据编辑下拉框
在新建或编辑的业务表单中,通常也会存在下拉框组件,用于从中选择候选数据,并将数据字典中的 ID 作为业务表字段值,提交到后台。
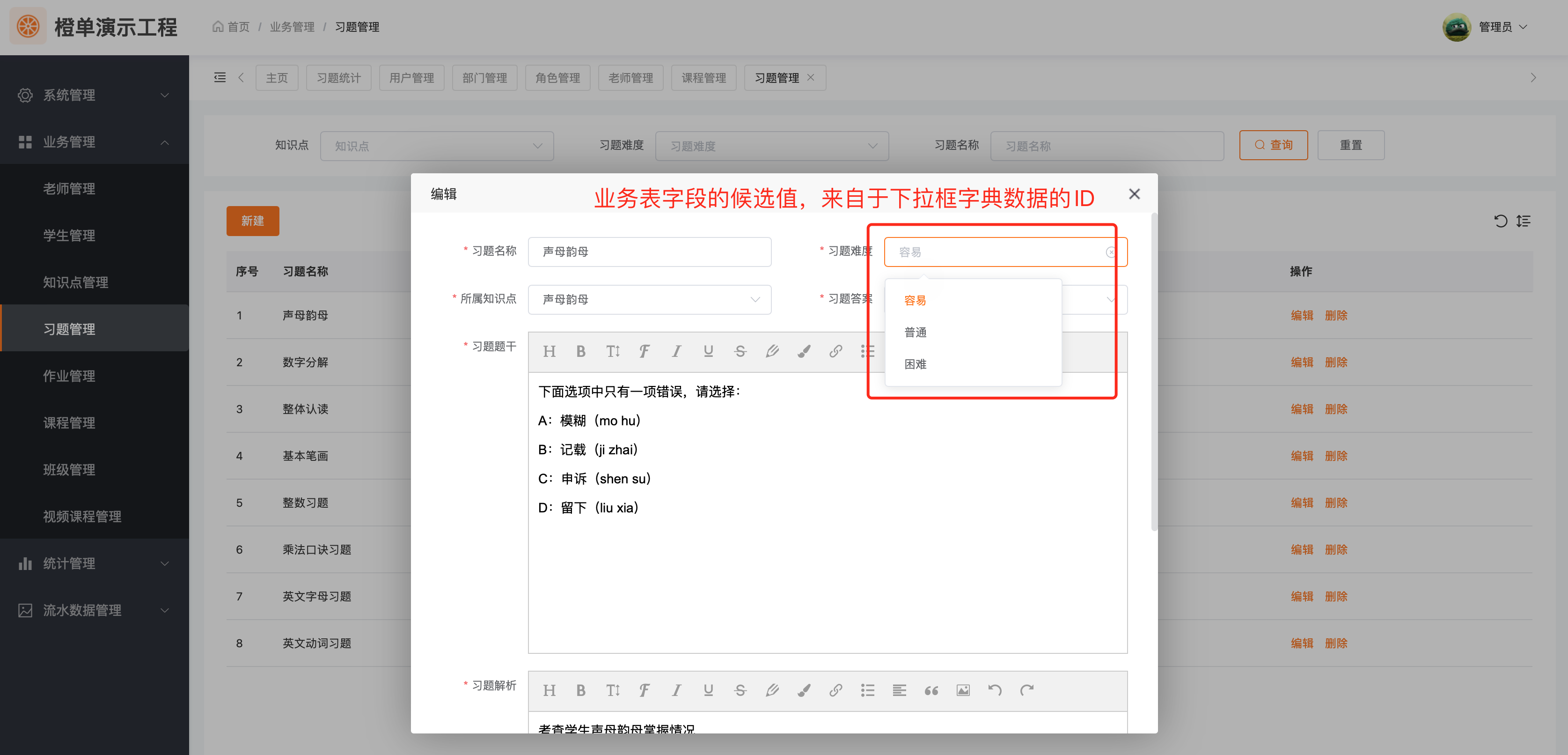
列表显示
在列表中,通常是后台会将字典翻译的结果返回给前端,前端按照统一约定的格式,直接显示即可。
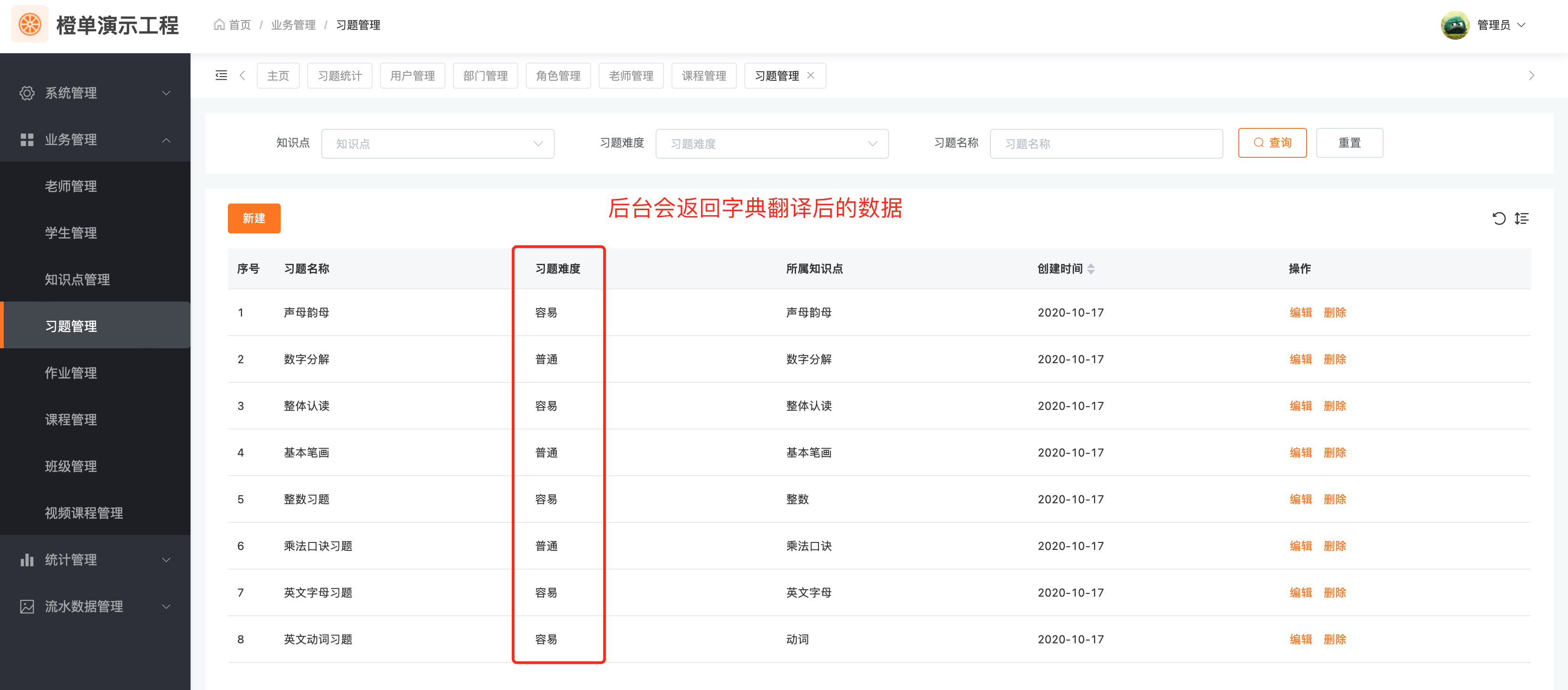
统计图表
图表中的维度数据,通常是后台将字典翻译的结果返回给前端,前端按照统一约定的格式,直接显示即可。
字典类型比对
在开始介绍每个类型的字典之前,我们先看一下他们之间的差别,以便于在系统设计中,可以做出更为合适的选择。
| 数据表支持 | 单独数据表 | 字典对象 | 请求接口 | 通用性 | 运行效率 | 数据更新 | 字典缓存 | 树形结构 | |
|---|---|---|---|---|---|---|---|---|---|
| 常量字典 | 无 | 无 | 常量类 | 无 | 一般 | 最高 | 不支持 | 内存 | 不支持 |
| 全局编码字典 | 有 | 否 | 公用字典类 | 有 | 最高 | 高 | 支持 | Redis | 不支持 |
| 数据表字典 | 有 | 是 | 表实体对象 | 有 | 较高 | 低 | 支持 | 数据库 | 支持 |
| 字典表字典 | 有 | 是 | 表实体对象 | 有 | 一般 | 高 | 支持 | Redis | 支持 |
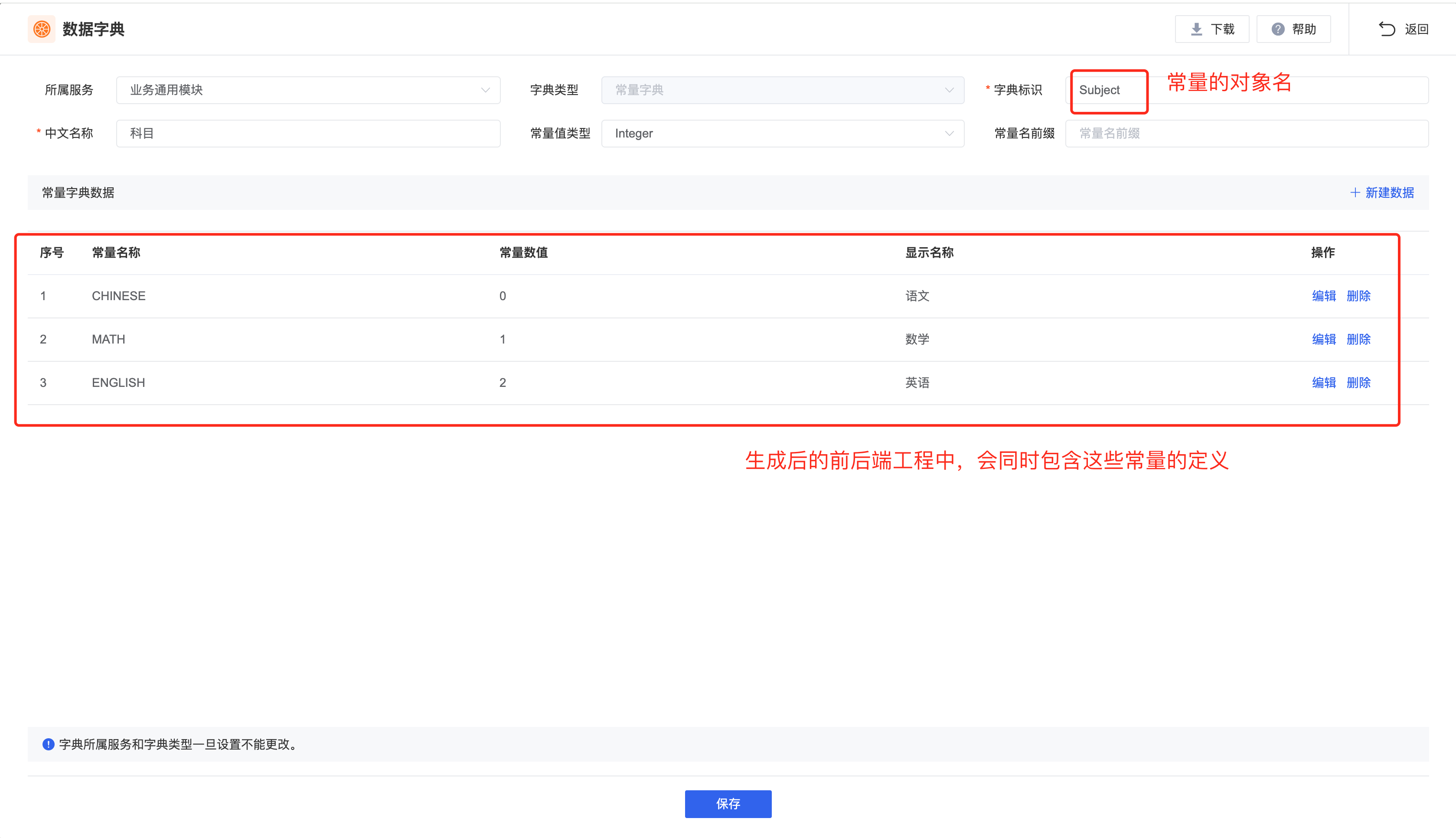
常量字典
常量字典的定义会同时出现在前后端工程的代码中,且数据定义必须保持一致。
代码生成
在生成后的工程中,没有前端页面可以用于动态配置常量字典值。
字典数据翻译
常量字典在生成后工程中的实现细节,主要为以下几点。
- 在生成后的后台工程中,每个常量字典会生成一个与之对应的 Java 常量类。
- 生成后的前端工程中,也会包含该常量字典的定义代码。
- 数据验证和字典翻译,都是在前后端的内存中完成,因此效率最高。
- 一旦字典数据发生变化,需要同时修改前后端代码,并重新部署。
以下代码为自动生成的 Java 常量类,用于常量字典在后台的定义。
/**
* 科目常量字典对象。
*
* @author 橙单测试账号
* @date 2020-07-29
*/
public final class Subject {
// 语文。
public static final int CHINESE = 0;
// 数学。
public static final int MATH = 1;
// 英语。
public static final int ENGLISH = 2;
private static final Map<Object, String> DICT_MAP = new HashMap<>(3);
static {
DICT_MAP.put(CHINESE, "语文");
DICT_MAP.put(MATH, "数学");
DICT_MAP.put(ENGLISH, "英语");
}
// 判断参数是否为当前常量字典的合法值。
public static boolean isValid(Integer value) {
return value != null && DICT_MAP.containsKey(value);
}
}在以下实体对象中,我们使用 RelationConstDict 注解标注常量字典的翻译字段,同时字段名以 DictMap 结尾,字段类型为 Map。Map 中包含两个条目,分别是 id 和 name,其中 id 的值和当前实体对象的 subjectId 相同,name 为字典翻译值。如:{"id": 0, "name": "语文"}。
@Data
@TableName(value = "zz_course")
public class Course {
// ... ... 此处省略若干其他字段的定义。
// 学科。
@TableField(value = "subject_id")
private Integer subjectId;
// ... ... 此处省略若干其他字段的定义。
// Map值示例:{"id": 0, "name": "语文"}
@RelationConstDict(
masterIdField = "subjectId",
constantDictClass = Subject.class)
@TableField(exist = false)
private Map<String, Object> subjectIdDictMap;
}常量字典翻译过程如下。
- 根据以上代码中的注解参数 masterIdField ,知道当前实体类中 subjectId 字段是常量字典 Id 数据。
- 注解参数 constantDictClass,给出该字典对应的常量类。
- 单表查询后,提取结果集中所有 subjectId 字段的值,再到常量对象的 DICT_MAP 静态字段中逐个比对。
- 如相等,则将匹配后的常量值和对应的显示名,回填到注解标记的字段中,如上例的 subjectIdDictMap 字段。
全局编码字典
在大多数业务系统中,全局编码字典的应用是最为广泛的。通常情况下,应该成为数据字典的首选类型。
代码生成
在生成器中,我们仅需配置编码字典本身,至于每个全局编码字典所包含的字典值,需要在生成后工程的字典管理页面中配置。
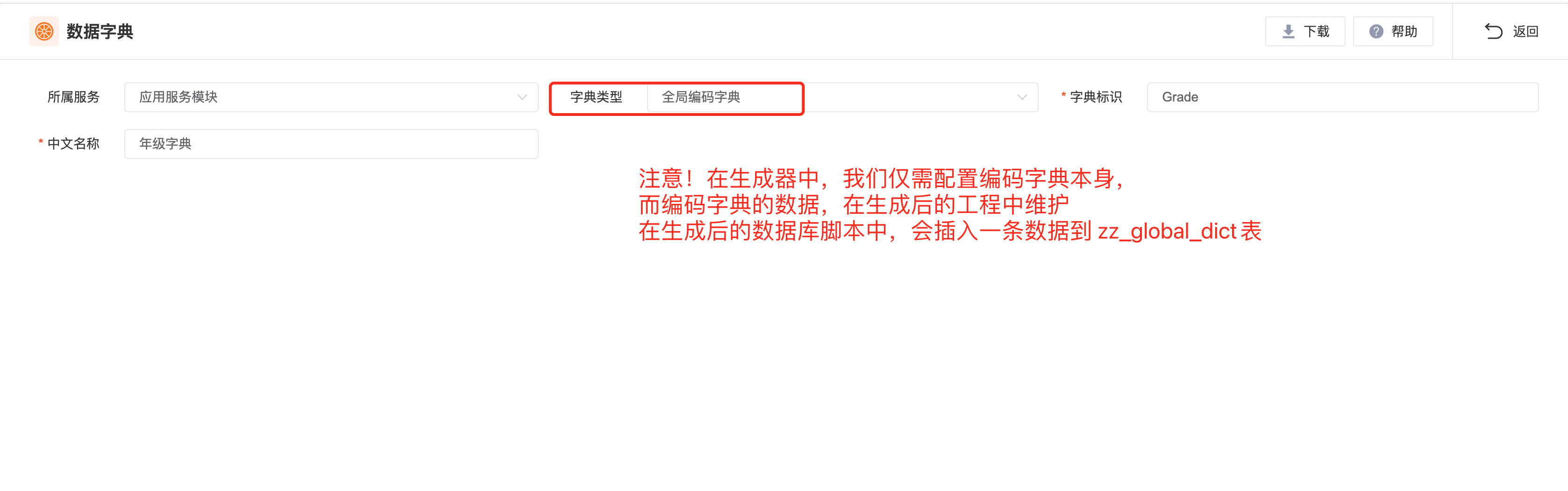
上图配置的全局编码字典,会在生成后工程的 global-dict-script.sql 文件中,包含如下插入语句。
INSERT INTO zz_global_dict VALUES (1522752162617102336/*自动生成的字典主键值*/,'Grade','年级字典',.../*省略其余字段*/)字典配置
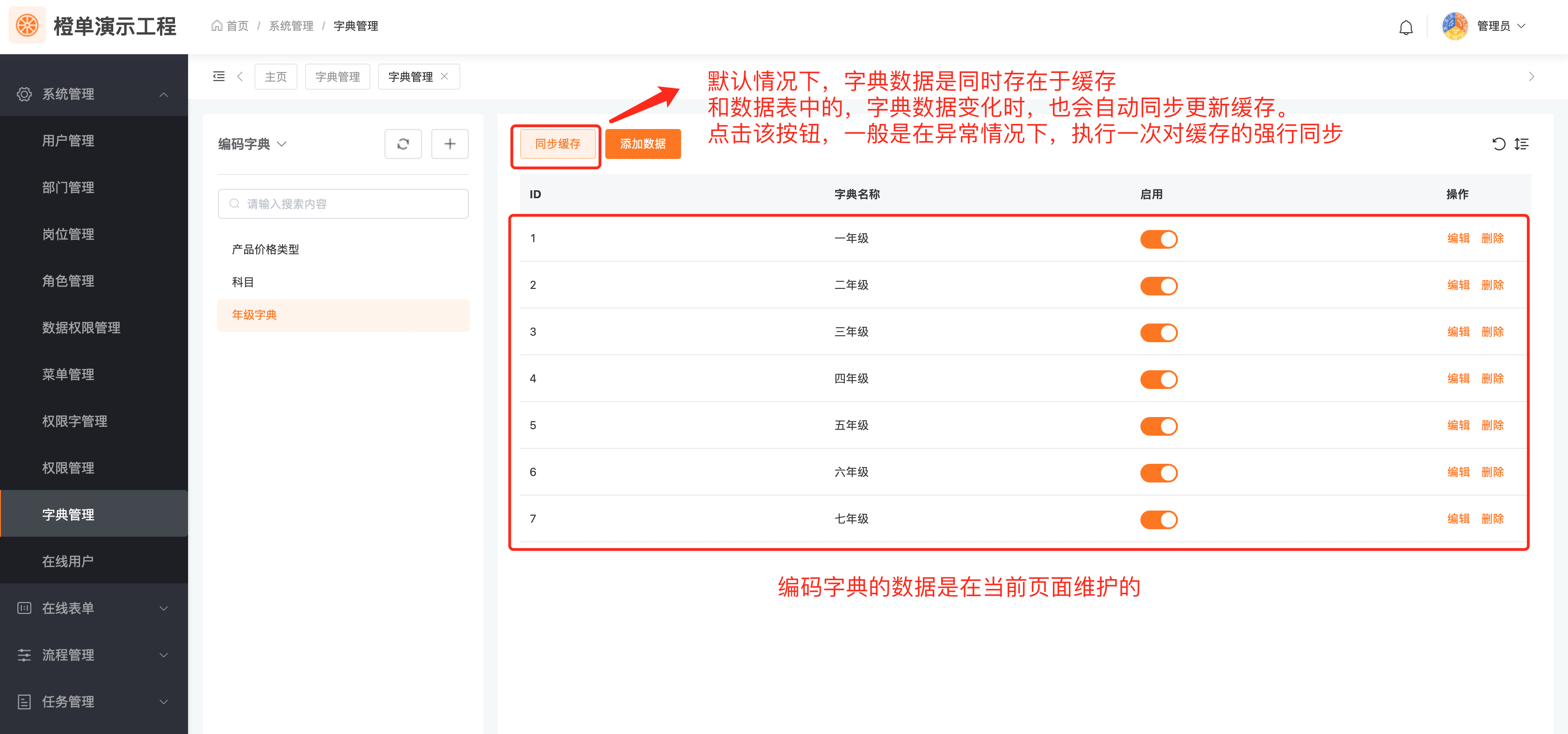
在生成后工程的「字典管理」页面,配置「全局编码字典」的字典数据。同时还可以在该页面「增删改」全局编码字典。
字典数据存储
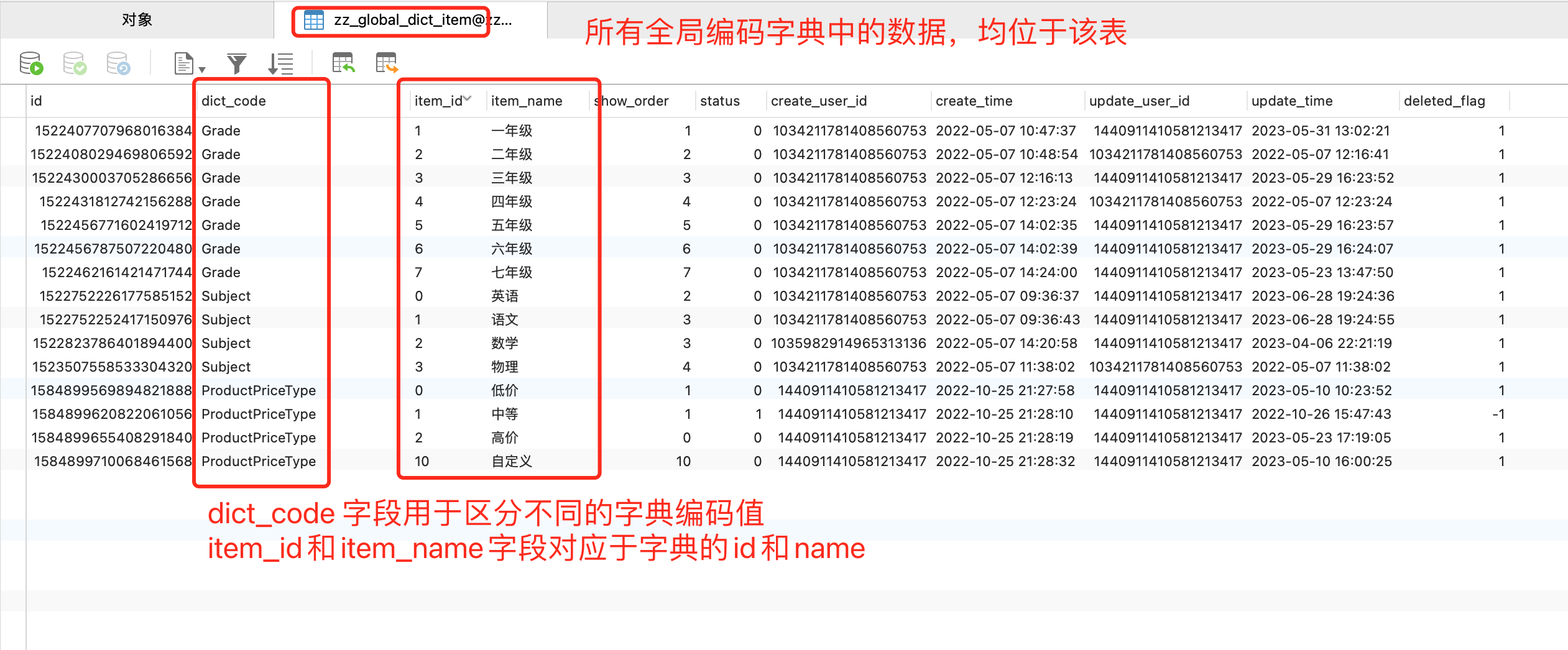
全局编码字典的定义位于 zz_global_dict 表中。
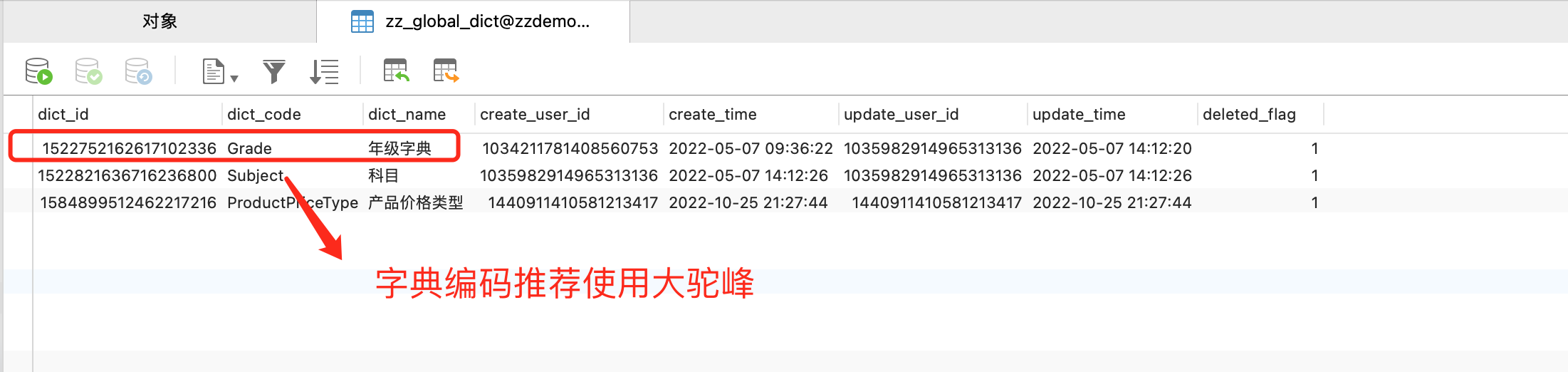
全局编码字典的数据位于 zz_global_dict_item 表中。
字典数据翻译
下面我们介绍一下全局编码字典的主要特征。
- 全局编码字典不支持树形结构。
- 通过不同的编码值,如上图中的 dict_code 字段,来区分不同类型的字典。
- 我们将编码值 (dict_code) 作为 Redis 缓存键值的一部分,并将所有全局编码字典数据存入 Redis 的不同键中。
- 无论是数据验证、字典翻译,还是字典列表,全部基于 Redis 缓存完成,因此效率很高。
- 在系统运行时,如果字典数据出现变化,可在字典管理页面进行数据维护,并即刻生效,无需重启任何应用服务。
在以下实体对象中,我们使用 RelationGlobalDict 注解标注全局编码字典的翻译字段,同时字段名以 DictMap 结尾,字段类型为 Map。Map 中包含两个条目,分别是 id 和 name,其中 id 的值和当前实体对象的 gradeId 相同,name 为字典翻译值。如:{"id": 1, "name": "一年级"}。
@Data
@TableName(value = "zz_course")
public class Course {
// ... ... 此处省略若干其他字段的定义。
// 年级。
@TableField(value = "grade_id")
private Integer gradeId;
// ... ... 此处省略若干其他字段的定义。
@RelationGlobalDict(
masterIdField = "gradeId",
dictCode = "Grade")
@TableField(exist = false)
private Map<String, Object> gradeIdDictMap;
}全局编码字典翻译过程如下。
- 根据以上代码中的注解参数 masterIdField ,知道当前实体类中 gradeId 字段是全局编码字典 Id 数据。
- 注解参数 dictCode,给出该字典的编码值。
- 单表查询后,提取结果集中所有 gradeId 字段的值并去重。
- 基于 RelationGlobalDict 注解的 dictCode 参数值 (Grade),计算出该字典的 Redis 缓存键值 (如 GlobalDict:Grade)。
- 利用上一步计算出的 Redis 缓存键值,同时基于第一步中获取的字典 Id 集合,去 Redis 中批量查询。
- 迭代业务主表数据集 (如课程结果集),与 Redis 中返回的字典数据集合逐个比对,如果相等,就回填到注解标记的字段中,如上例的 gradeIdDictMap 字段。
字典表字典
相比于全局编码字典,字典表字典唯一的优势就是可以设置为「支持缓存的树形字典」,除此之外,不再有其他的优势应用场景了。反之却有一些刚性的缺陷,因此在橙单中,我们正在逐步建议我们的开发者用户,尽量不再配置该类型的数据字典。具体劣势如下。
- 每个字典都需要一个单独的数据表支持,因此会导致后台 Controller/Service/ServiceImpl/Dao/Mapper/Model/Vo/Dto 过多。
- 新增字典时,需要新增数据表,同时也要修改前后端的代码,并重新部署前后端应用。
代码生成
在生成器中,我们仅需配置字典表字典本身,至于每个字典所包含的字典值,需要在生成后工程的字典管理页面中配置。此外,在生成后工程的数据库脚本中,也不会包含该字典的 INSERT SQL 语句。
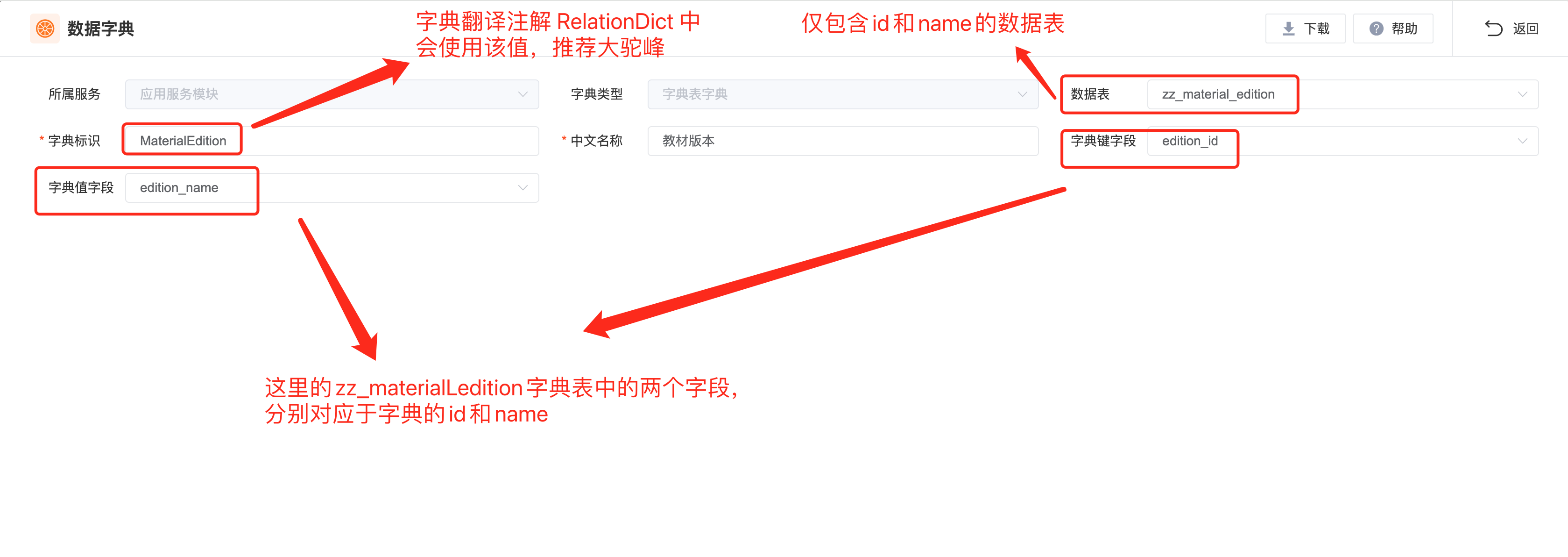
在生成后的后端工程中,会为该字典表字典生成与之对应的 Controller/Service/ServiceImpl/Dao/Mapper/Model/Vo/Dto 代码文件,如下图。

字典配置
在生成后工程的「字典管理」页面,配置「字典表字典」的字典数据。与全局编码字典不同的是,在该页面不能「增删改」字典本身。

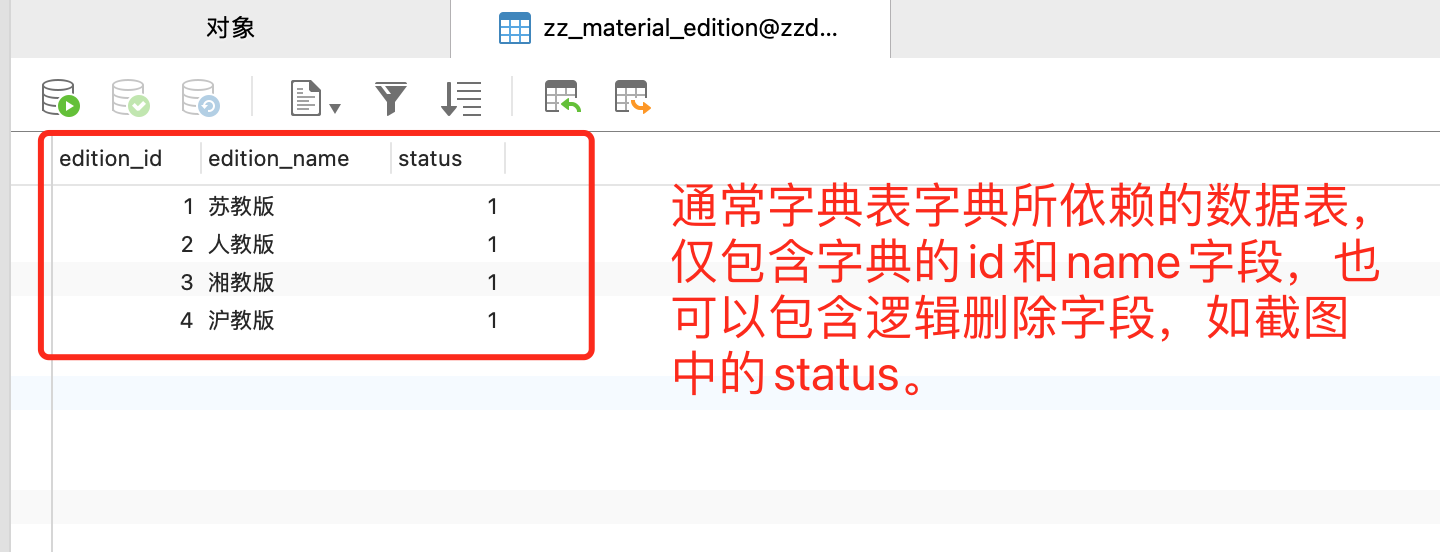
字典数据存储
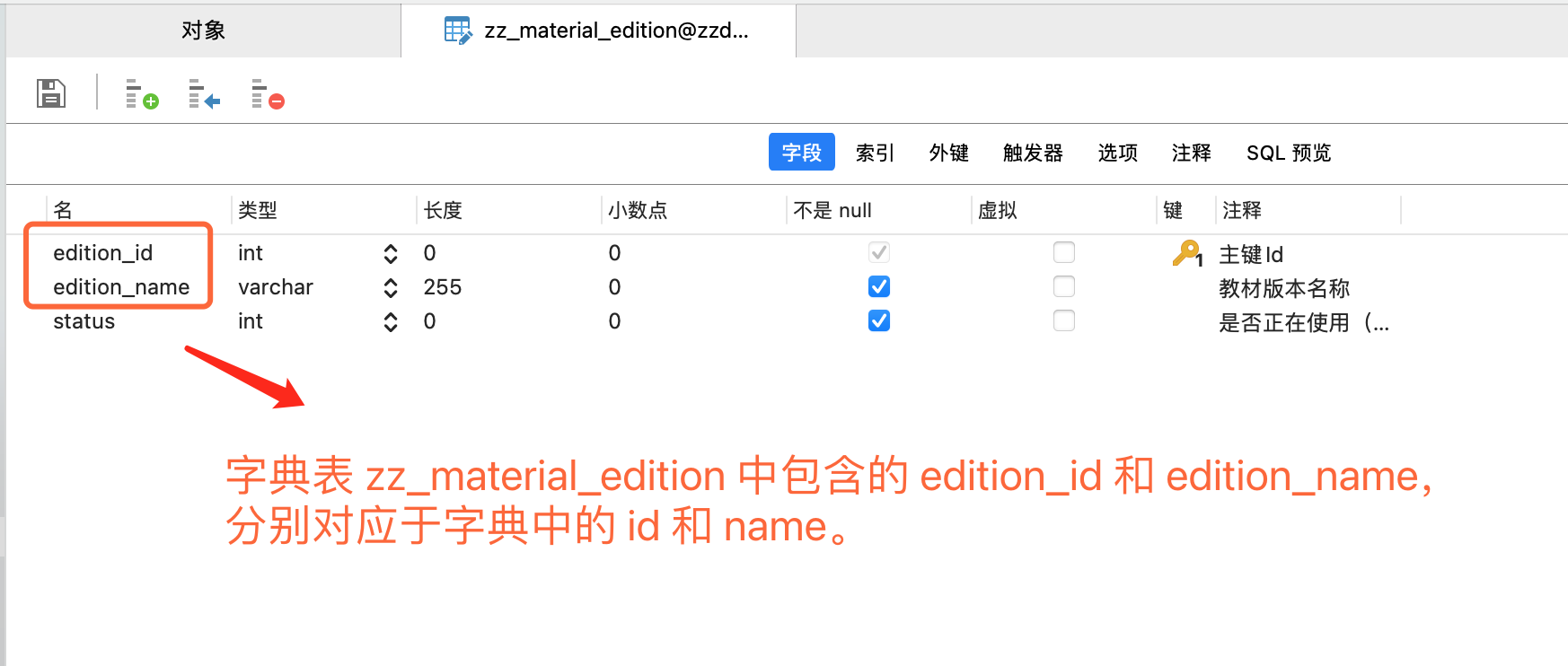
每个字典表字典都会依赖一个数据表,如以下截图中的 zz_material_edition。此类字典表通常仅包含字典 ID、字典 NAME 和逻辑删除字段,并且字典表内数据量较少。
字典数据翻译
在以下实体对象中,我们使用 RelationDict 注解标注字典表字典的翻译字段,同时字段名以 DictMap 结尾,字段类型为 Map。Map 中包含两个条目,分别是 id 和 name,其中 id 的值和当前实体对象的 editionId 相同,name 为字典翻译值。如:{"id": 1, "name": "苏教版"}。
/**
* 知识点实体对象。
*
* @author Jerry
* @date 2020-01-01
*/
@Data
@TableName(value = "zz_knowledge")
public class Knowledge {
// ... ... 忽略其余不相干的字段。
// 教材版本。
@TableField(value = "edition_id")
private Integer editionId;
@RelationDict(
masterIdField = "editionId",
slaveModelClass = MaterialEdition.class,
slaveIdField = "editionId",
slaveNameField = "editionName")
@TableField(exist = false)
private Map<String, Object> editionIdDictMap;
}重要注意事项
字典表字典依赖数据库中的字典表,如上例中的教材版本字典 MaterialEdition,其依赖表为 zz_material_edition。
- 生成后的工程中,字典管理页面的字典表字典空空如也。
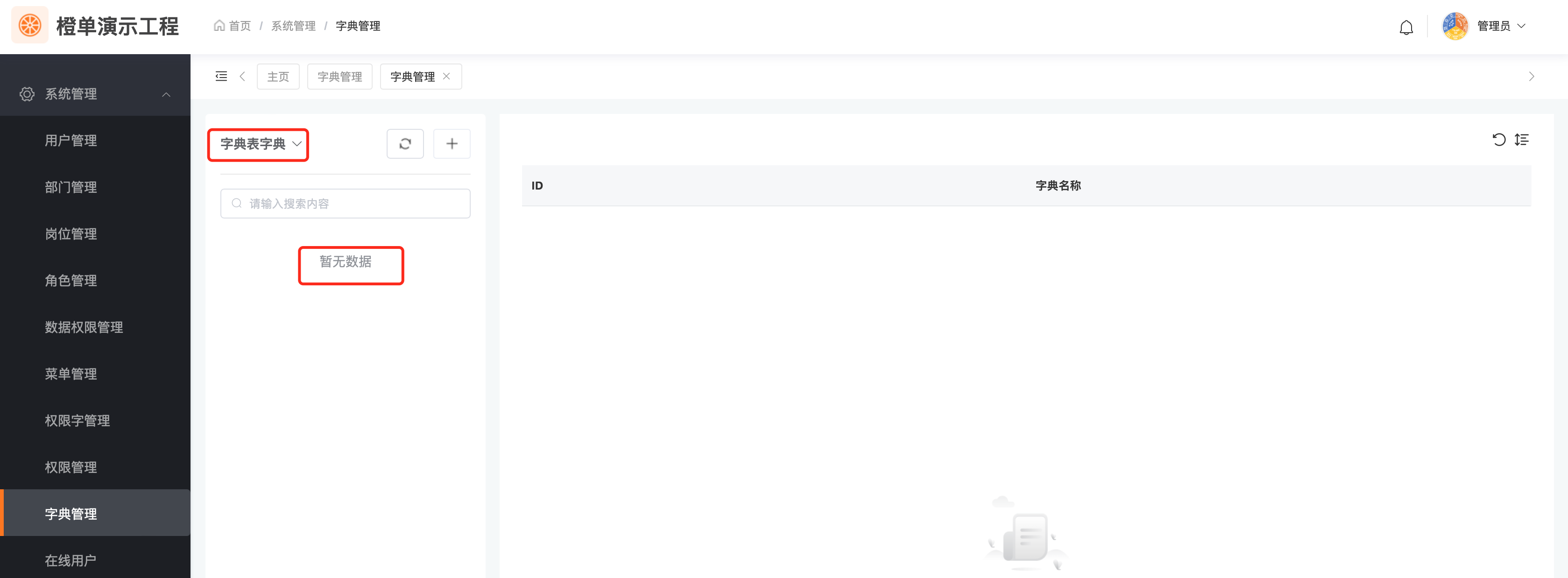
- 在生成器中配置字典表字典,重新生成前后端工程、打包并重新部署前后端工程。
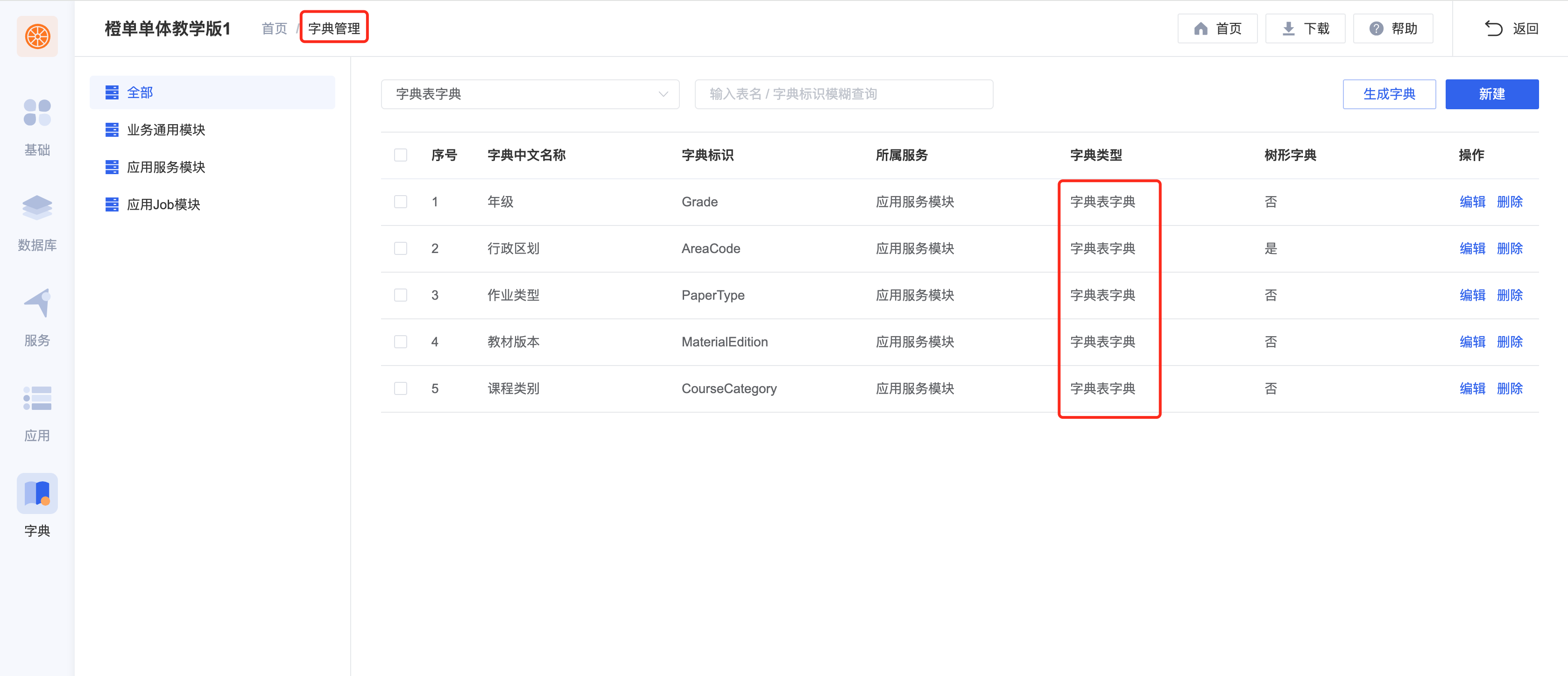
- 再次启动新生成的前后端工程,效果如下。
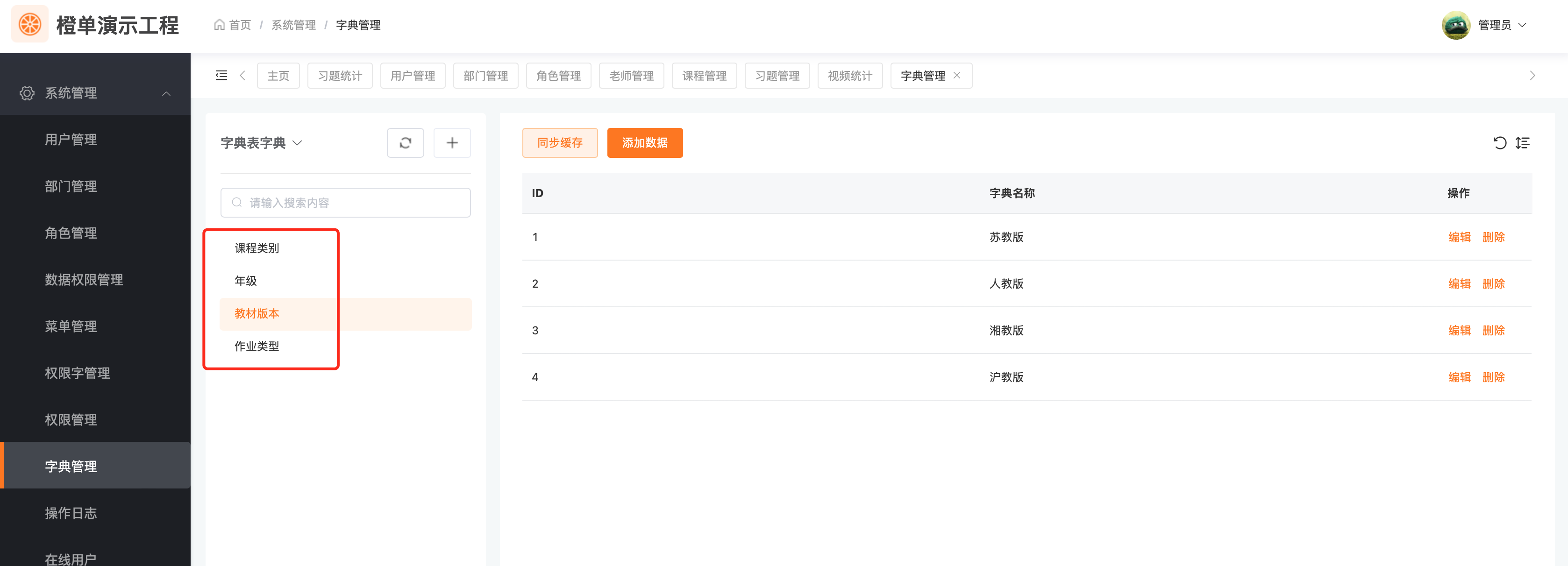
数据源字典
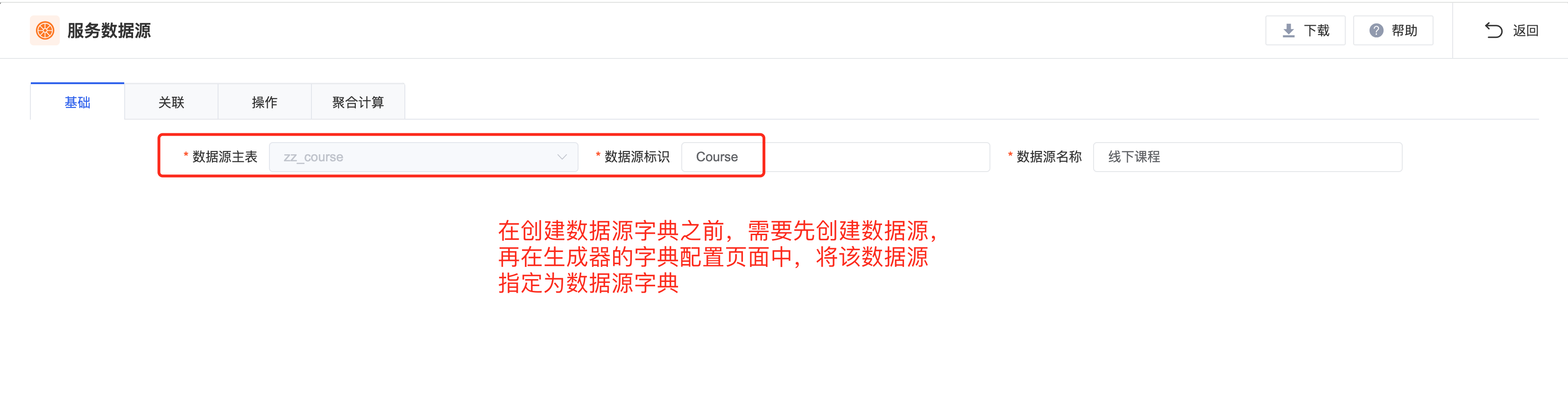
相比于其他字典类型,数据源字典极大的丰富了数据字典的应用场景。试想一下,任何业务表只要指定了字典映射字段,便能以字典的形式,在业务系统中,被其他业务表关联使用,这将是极为灵活且规范的。这里需要重点说明一下的是,相比于字典表字典和全局编码字典,数据源字典没有专门的字典数据维护页面,因为他的数据管理源于业务表页面的 「增删改」功能。
代码生成
在生成器中,我们仅需配置数据源字典本身,至于每个字典包含的字典值,均来自于该字典所依赖的业务表数据。此外,在生成后工程的数据库脚本中,也不会包含该字典的 INSERT SQL 语句。
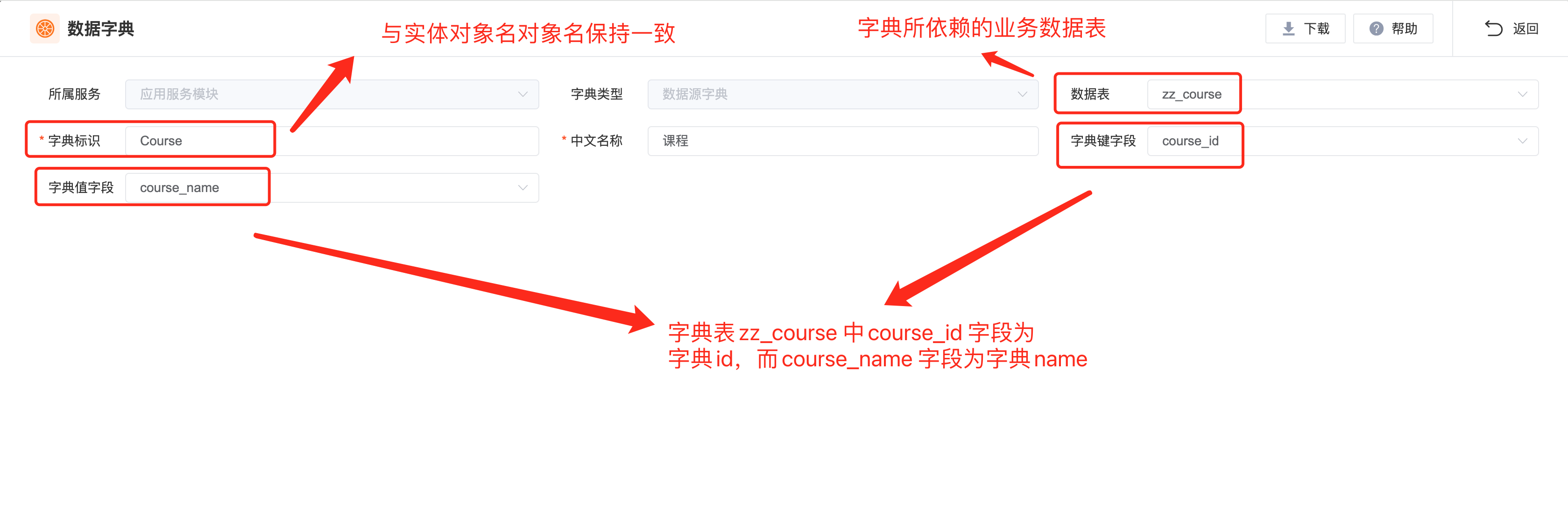
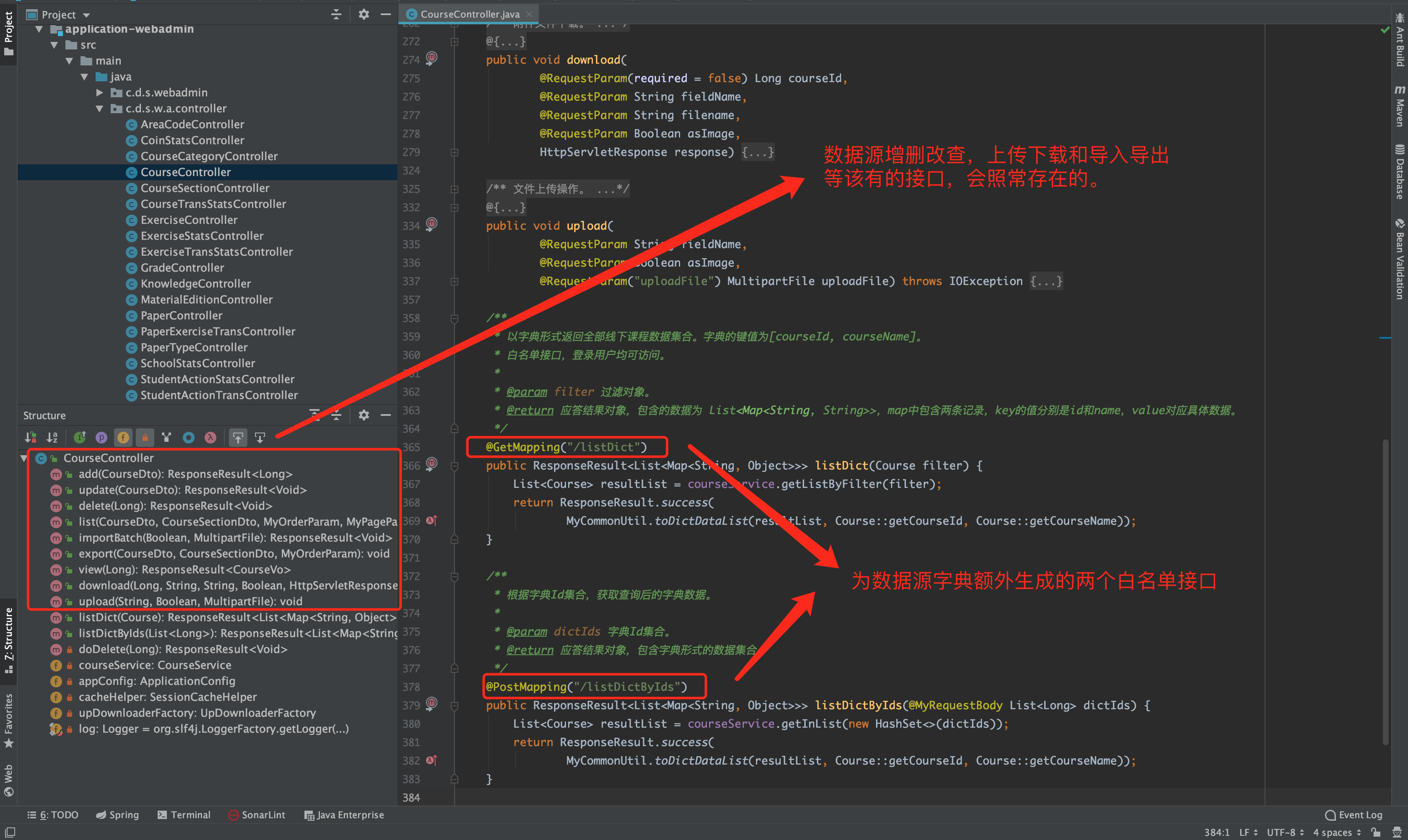
在生成后的 Controller 接口代码文件中,如下图的 CourseController。会照常生成普通数据源该有的接口方法,如增删改查、上传下载和导入导出等标准化业务接口。除此之外,还会生成两个与数据源字典相关的白名单接口 listDict 和 listDictByIds,前者用于读取字典列表数据,而后者会根据参数中的字典 IDs,返回对应的字典数据。
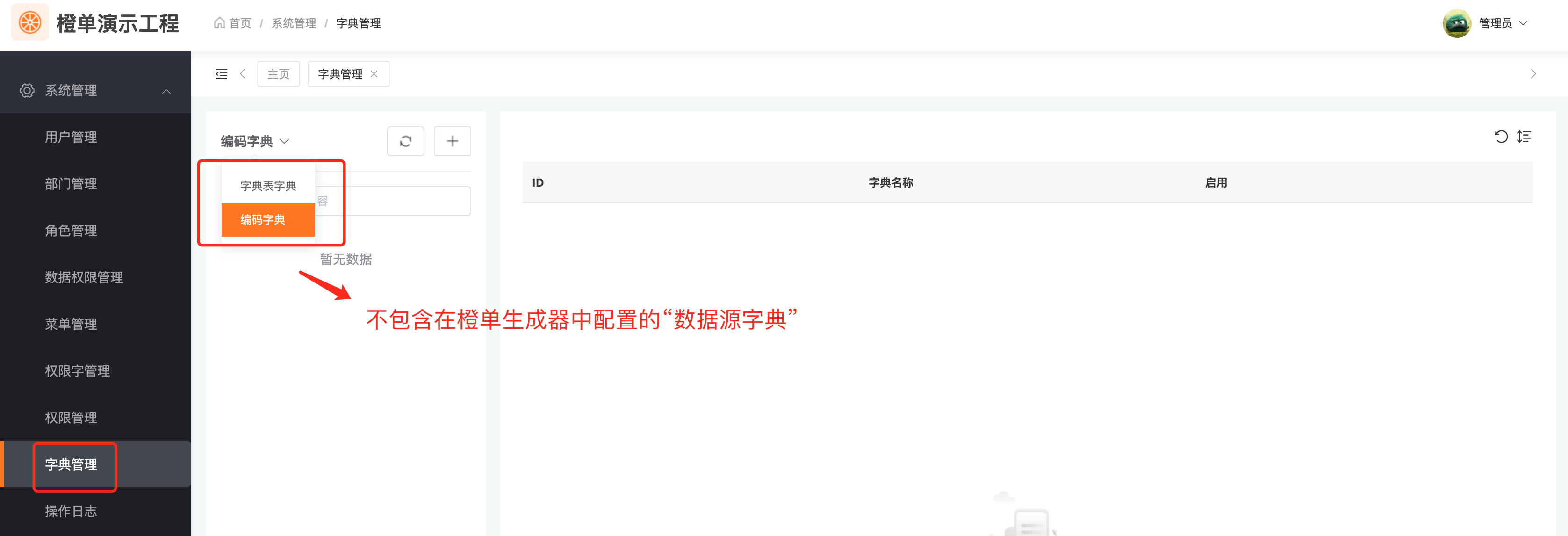
字典配置
字典管理页面无法维护「数据源字典」的数据。
数据源字典只是从业务表中指定了两个字段,分别映射为字典 ID 和字典 NAME。因此该类字典的数据,是由数据源字典表所对应的业务表单负责维护的。
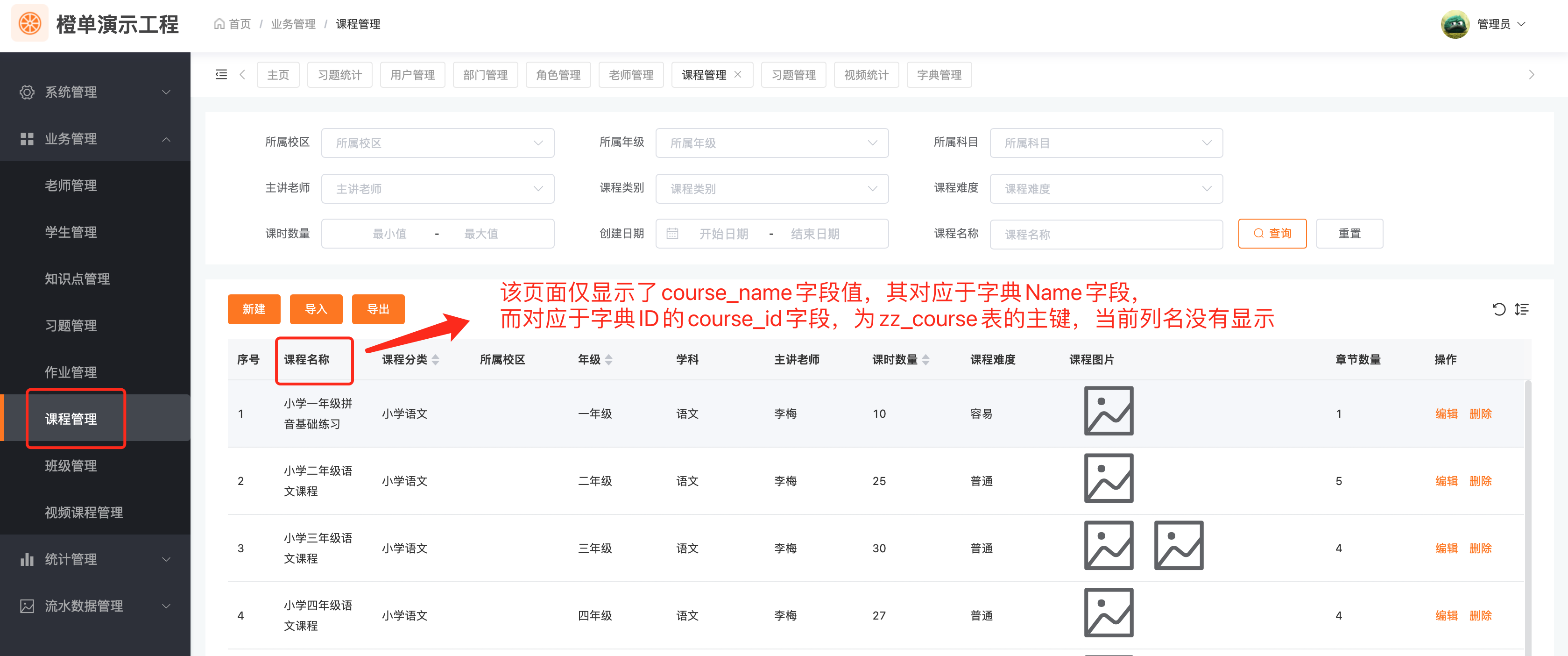
字典数据存储
与字典表字典相同的是,同样需要「独立的数据表」支持。而两者之间的差异,主要为以下两点。
- 字典表字典对应的数据表,通常仅包含字典 ID 和字典 NAME 字段,同时表数据量较少。
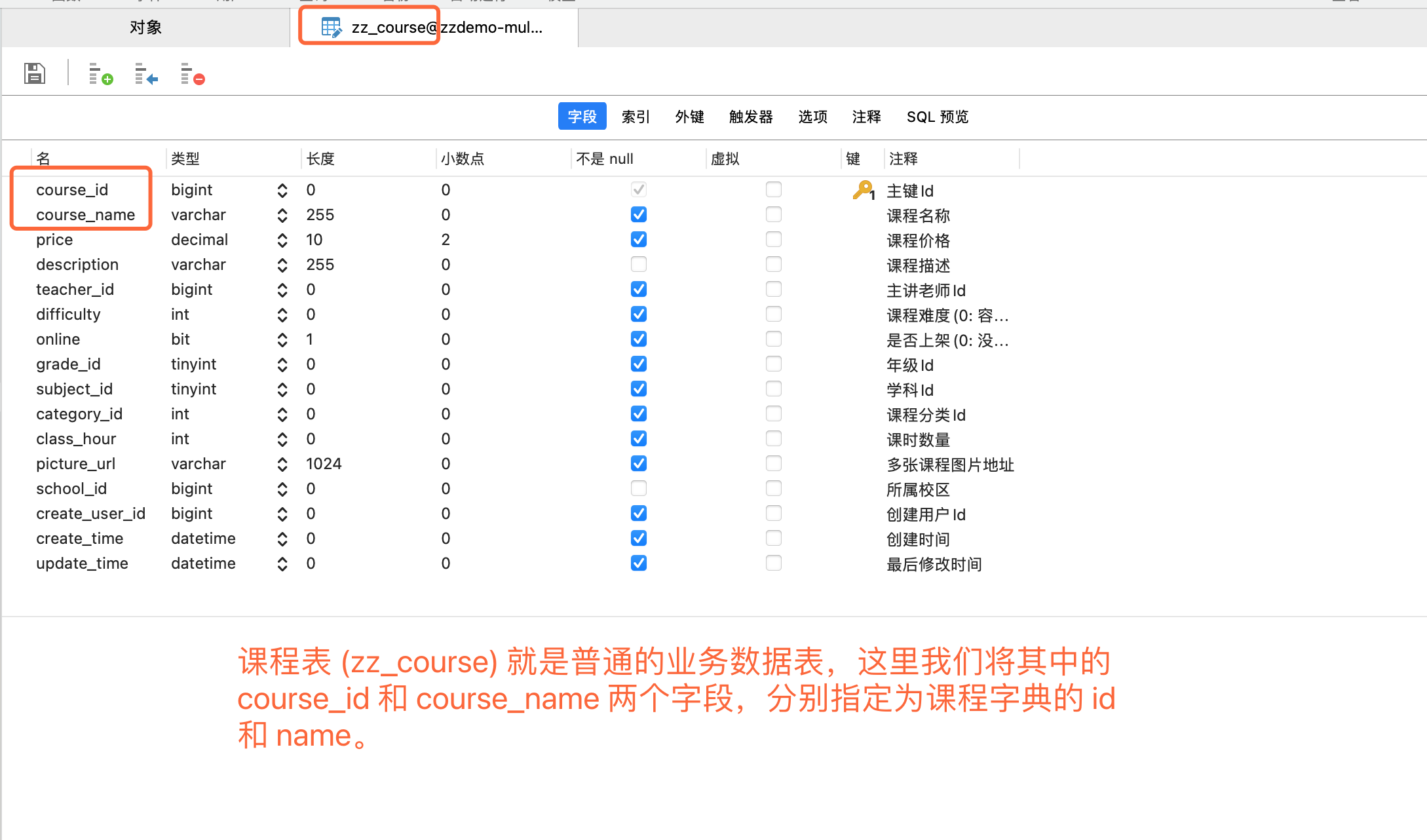
- 数据表字典对应的数据表,通常就是普通的业务数据表,只是其中的两个字段被映射为字典数据的 ID 和 NAME。
字典数据获取
所有支持数据源字典的 Controller 对象,都会包含白名单接口 listDict。该接口仅返回映射为字典 ID 和字典 NAME 的两个字段值,如本例的 courseId 和 courseName。由以下代码可以看出,数据源字典无缓存,所有字典数据的获取,均会与数据库产生交互。
数据表字典之所以没有缓存,是因为字典数据来自于业务表,而业务表数据通常变化较为频繁,且数据量较大。
// 与普通字典表的接口一样,都定义为listDict。
@GetMapping("/listDict")
public ResponseResult<List<Map<String, Object>>> listDict(Course filter) {
// 这一步就是从数据库中去取,同时还支持过滤条件。
List<Course> resultList = courseService.getListByFilter(filter);
// 与其他字典一样的是,返回给前端的字典数据,同样是id和name。
return ResponseResult.success(BeanQuery.select(
"courseId as id", "courseName as name").executeFrom(resultList));
}字典数据翻译
在以下实体对象中,我们使用 RelationDict 注解标注数据源字典的翻译字段,同时字段名以 DictMap 结尾,字段类型为 Map。Map 中包含两个条目,分别是 id 和 name,其中 id 的值和当前实体对象的 schoolId 相同,name 为字典翻译值。如:{"id": 1, "name": "朝阳校区"}。
/**
* 课程实体对象。
*
* @author Jerry
* @date 2020-01-01
*/
@Data
@TableName(value = "zz_course")
public class Course {
// ... ... 忽略其余不相干的字段。
// 所属校区。
@TableField(value = "school_id")
private Long schoolId;
@RelationDict(
masterIdField = "schoolId",
equalOneToOneRelationField = "sysDept",
slaveModelClass = SysDept.class,
slaveIdField = "deptId",
slaveNameField = "deptName")
@TableField(exist = false)
private Map<String, Object> schoolIdDictMap;
}应用代码分析
本小节将重点介绍与数据字典相关的后台应用代码实现逻辑。
字典缓存
在业务系统中,数据字典的使用是极为高频的。就目前而言,我们对不同类型的字典数据采用了不同形式的缓存机制,以此尽可能的减少与数据库的交互次数,提升系统的整体运行效率,具体缓存机制如下。
- 常量字典。前后端全部内存操作,运行时效率最高。
- 全局编码字典。字典数据全量缓存到 Redis,数据发生变化时,可自动同步到 Redis 缓存,运行时效率较高。
- 字典表字典。字典数据全量缓存到 Redis,数据发生变化时,可自动同步到 Redis 缓存,运行时效率较高。
- 数据源字典。字典数据来源于业务数据表,业务数据变化频度相对较高,且数据量不可控,可能会较大,因此无缓存,运行时效率不高。
缓存同步
尽管橙单的底层架构,为字典缓存同步提供了较好的实现逻辑,然而我们也充分考虑到,生产环境中可能会出现各种极端的场景。为此我们提供了缓存和数据库数据的比对接口,并在前端实现了字典数据一致性的比对逻辑。该操作仅应用于「全局编码字典」和「字典表字典」,见如下截图。
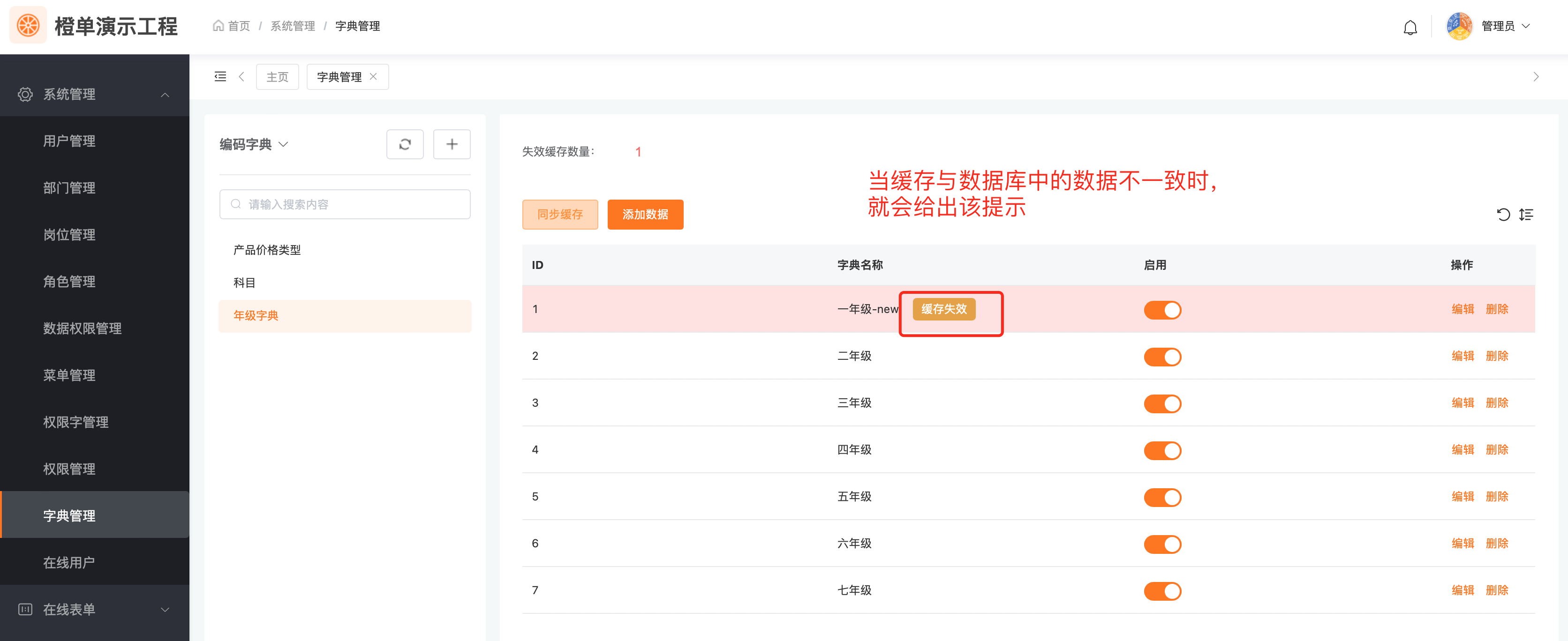
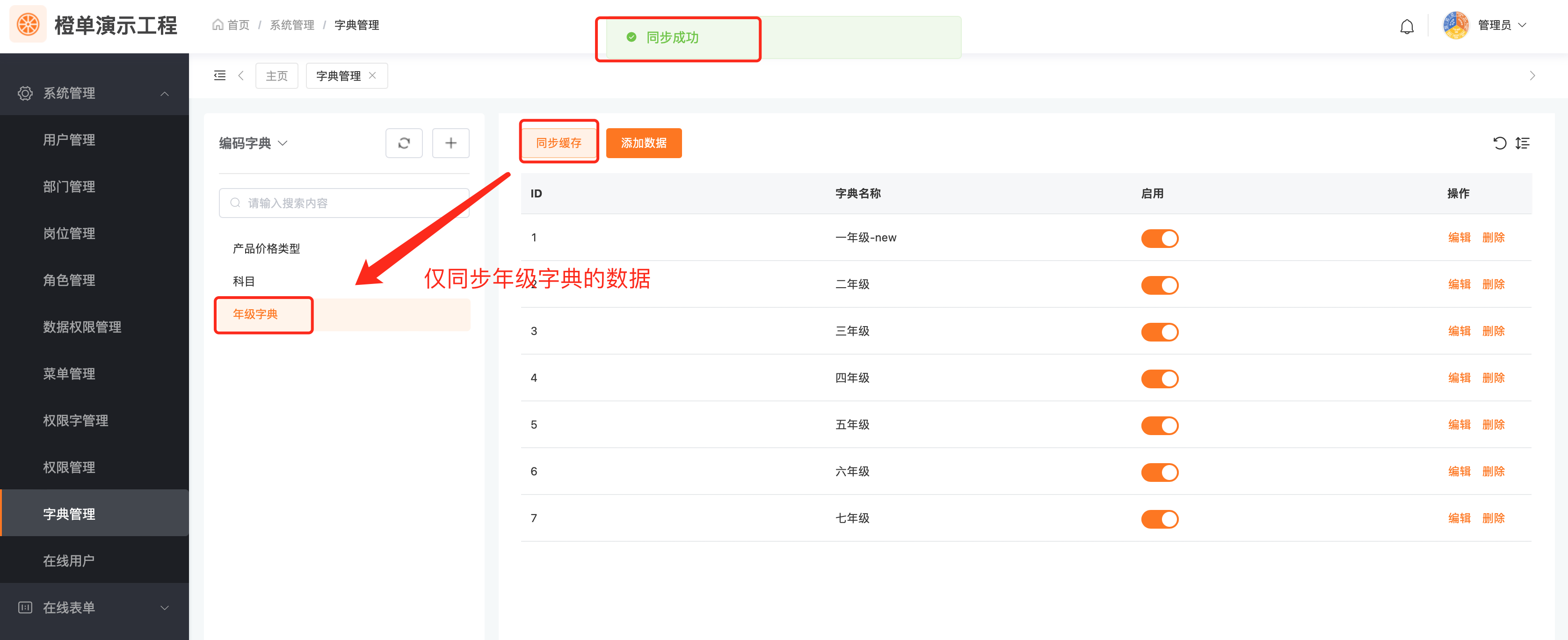
点击下图的「同步缓存」按钮,对于该字典数据,即可完成一次从数据库到 Redis 缓存的强制全量同步,更新后结果如下图所示。
以下代码为全局编码字典数据比对功能所调用的后台接口,具体实现可见如下代码及关键性注释。
@Slf4j
@RestController
@RequestMapping("/admin/upms/globalDict")
public class GlobalDictController {
// ... ... 忽略该接口的其余代码实现。
@GetMapping("/listAll")
public ResponseResult<JSONObject> listAll(@RequestParam String dictCode) {
// 从数据库中读取全部字典数据。
List<GlobalDictItem> fullResultList =
globalDictItemService.getGlobalDictItemListByDictCode(dictCode);
// 从缓存中读取全部字典数据。
List<GlobalDictItem> cachedList =
globalDictService.getGlobalDictItemListFromCache(dictCode, null);
JSONObject jsonObject = new JSONObject();
// GlobalDictItem对象的itemId和itemName字段,分别对应于字典的id和name。
// 在以下的toDictDataList方法中会完成字段映射。
jsonObject.put("fullResultList", this.toDictDataList2(fullResultList));
jsonObject.put("cachedResultList", this.toDictDataList2(cachedList));
return ResponseResult.success(jsonObject);
}
}以下代码为「同步缓存」按钮调用的全局编码字典后台接口,见如下代码。
@Slf4j
@RestController
@RequestMapping("/admin/upms/globalDict")
public class GlobalDictController {
// ... ... 忽略该接口的其余代码实现。
@GetMapping("/reloadCachedData")
public ResponseResult<Boolean> reloadCachedData(@RequestParam String dictCode) {
globalDictService.reloadCachedData(dictCode);
return ResponseResult.success(true);
}
}字典数据列表
下图是业务系统中数据字典的常用应用场景。
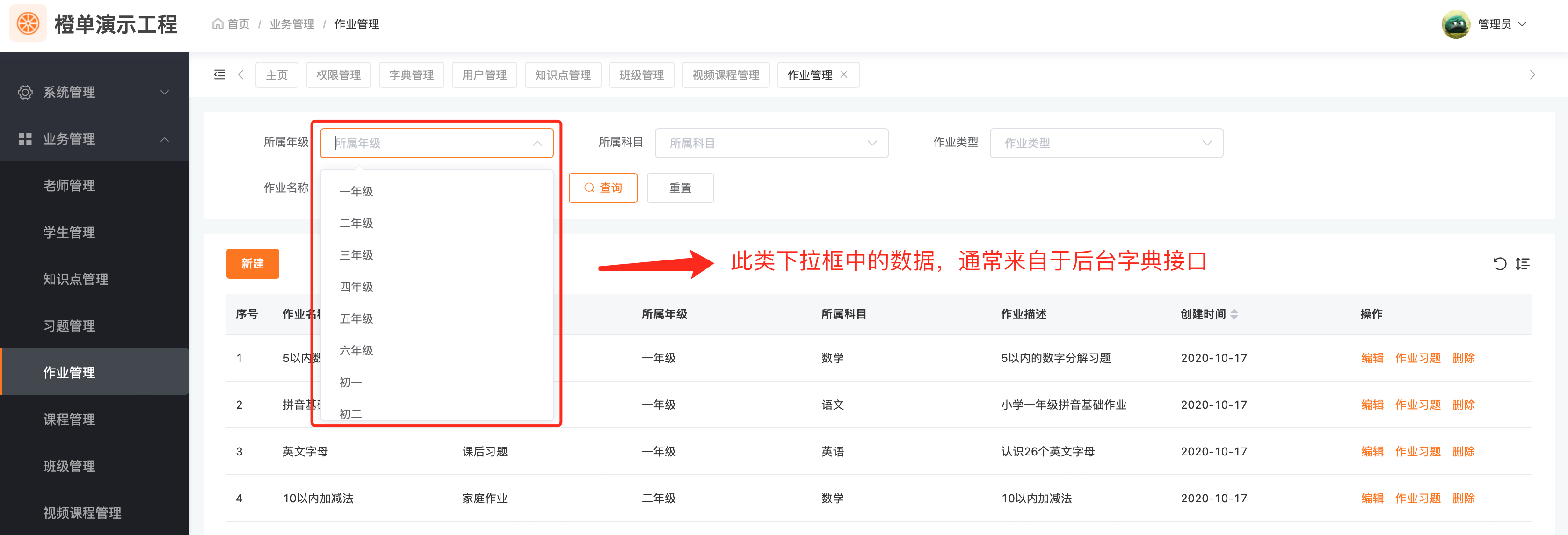
基于常量字典的下拉框数据,前端会在其代码内部解决。而全局编码字典、字典表字典和数据源字典,前端都会调用后台接口获取字典数据。见如下代码中的 listDict 接口,所有字典均会提供该接口,以保证代码的统一规范性。这里仅以最为常用的全局编码字典代码实现为例。
@Slf4j
@RestController
@RequestMapping("/admin/upms/globalDict")
public class GlobalDictController {
public ResponseResult<List<Map<String, Object>>> listDict(@RequestParam String dictCode) {
// ... ... 忽略该接口的其余代码实现。
@GetMapping("/listDict")
public ResponseResult<List<Map<String, Object>>> listDict(@RequestParam String dictCode) {
// 直接从缓存中读取字典数据了
List<GlobalDictItem> resultList =
globalDictService.getGlobalDictItemListFromCache(dictCode, null);
resultList = resultList.stream()
.sorted(Comparator.comparing(GlobalDictItem::getStatus))
.sorted(Comparator.comparing(GlobalDictItem::getShowOrder))
.collect(Collectors.toList());
return ResponseResult.success(this.toDictDataList(resultList));
}
}数据编辑
下图是业务系统中数据字典的常用应用场景。
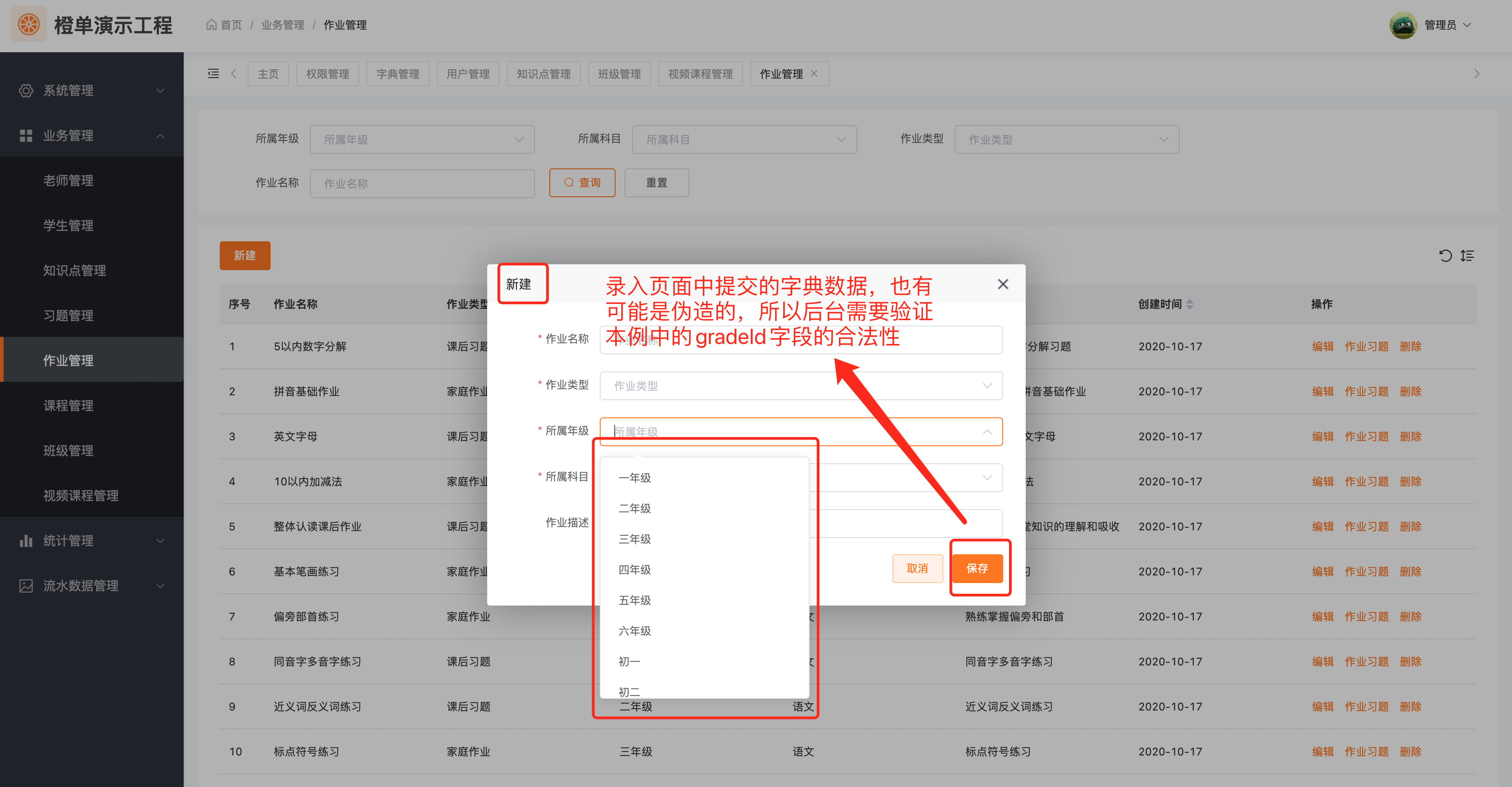
数据新建和编辑接口的代码比较近似,这里我们仅给出 add 接口的代码实现。其中调用的 verifyRelatedData 方法实现了单条字典数据的验证逻辑。
// 下面的add方法位于Controller类内。
@PostMapping("/add")
public ResponseResult<Long> add(@MyRequestBody KnowledgeDto knowledgeDto) {
// 基于Validator注解的数据合法性验证,比如是否非空,是否符合正则模式,是否超出长度等。
String errorMessage = MyCommonUtil.getModelValidationError(knowledgeDto, false);
if (errorMessage != null) {
return ResponseResult.error(ErrorCodeEnum.DATA_VALIDATED_FAILED, errorMessage);
}
Knowledge knowledge = MyModelUtil.copyTo(knowledgeDto, Knowledge.class);
// 这里是重点,下面会给出KnowledgeService.verifyRelatedData的实现。
// 该方法会完成本例中,年级字典值gradeId的合法性验证。
CallResult callResult = knowledgeService.verifyRelatedData(knowledge, null);
if (!callResult.isSuccess()) {
return ResponseResult.errorFrom(callResult);
}
knowledge = knowledgeService.saveNew(knowledge);
return ResponseResult.success(knowledge.getKnowledgeId());
}// 以下代码位于业务的ServiceImpl类内。主要功能是验证单条字典数据的合法性。
@Override
public CallResult verifyRelatedData(Knowledge knowledge, Knowledge originalKnowledge) {
String errorMessageFormat = "数据验证失败,关联的%s并不存在,请刷新后重试!";
// 下面代码调用的是existId,由此可以看出是单条验证。
// 对于新增录入而言,因为原数据对象是null,所以一定会被验证。
// 对于编辑而言,只有当字典Id数据发现变化了,才会验证,否则无需验证。从而提升效率。
if (this.needToVerify(knowledge, originalKnowledge, Knowledge::getGradeId)
// 非常重要的一点,这里字典数据的验证是基于缓存的。第一个参数是字典的编码值。
&& !globalDictService.existDictItemFromCache("Grade", knowledge.getGradeId())) {
return CallResult.error(String.format(errorMessageFormat, "年级"));
}
return CallResult.ok();
}查询列表
通常而言,后台数据库表中保存的是字典 ID,如 gradeId,但在前端表格中需要显示的则是字典显示值,如 gradeName。见如下截图。
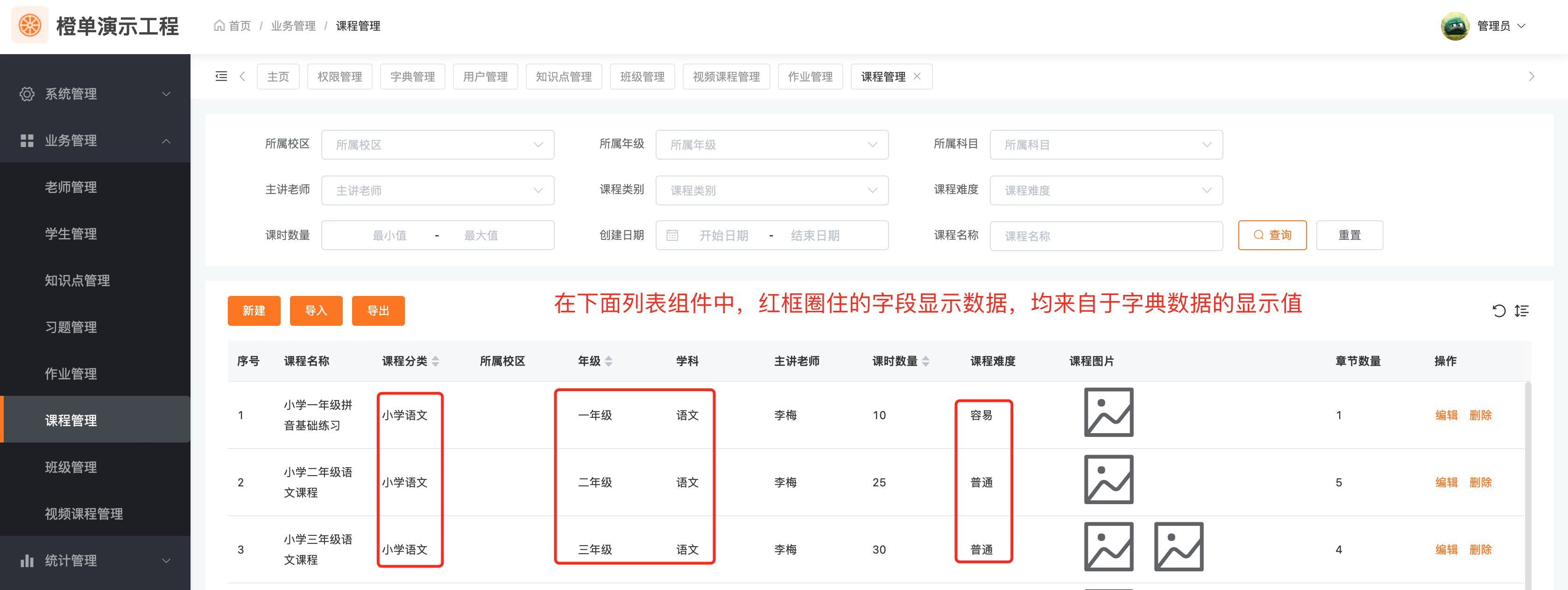
下面先给出业务数据列表接口 (/list) 的代码。其中调用的 getCourseListWithRelaiton 方法,实现了主表数据查询和字典数据的批量翻译。至于 getCourseListWithRelaiton 方法的实现,会在随后的代码片段中给出。在最后的实体类代码片段中,可以看到所有的字典数据都是按照Map的方式返回,其中 id 为数据表中的字典 ID 值,name 为翻译后的字典显示值,有了这些统一的字典数据返回格式,前端就可以以同样的方式处理所有字典数据了。
// 下面的list方法位于Controller类内。
@PostMapping("/list")
public ResponseResult<MyPageData<CourseVo>> list(
@MyRequestBody CourseDto courseDtoFilter,
@MyRequestBody MyOrderParam orderParam,
@MyRequestBody MyPageParam pageParam) {
// ... ... 略过其他字典字段的验证逻辑若干行。
// getCourseListWithRelation方法,实现了主表(本例中的课程表)的数据分页查询,并对分页结果进行批量的字典翻译。
List<Course> courseList =
courseService.getCourseListWithRelation(courseFilter, orderBy);
return ResponseResult.success(MyPageUtil.makeResponseData(courseList, Course.INSTANCE));
}// 以下代码位于业务的ServiceImpl类内。主要功能是先从主表查询数据,
// 再从缓存中批量获取字典数据,字典翻译匹配后,绑定到返回的主表对象列表中。
@Override
public List<Course> getCourseListWithRelation(Course filter, String orderBy) {
// 先从主表中获取查询结果,这里会规避与字典表的SQL关联。
List<Course> resultList = courseMapper.getCourseList(filter, orderBy);
// 字典数据位于Redis缓存,下面的字典字段翻译和数据绑定,都是批量完成的。
// 从缓存中一次性获取所有的字典Id数据,然后再在内存中,进行与主表数据集的数据组装。
// 这里只是对分页后的字典数据进行缓存检索,因此也可以有效的降低redis的网络开销。
this.buildRelationForDataList(resultList, MyRelationParam.normal());
return resultList;
}// 以下代码位于业务主表的实体类中,
// 上面的buildRelationForDataList方法,会根据下面的注解,为不同类型的字典进行字典翻译的。
@Data
@TableName(value = "zz_course")
public class Course {
// ... ... 这里省略了若干其他字段的定义。
// 用于组装全局编码字典的注解。
@RelationGlobalDict(
masterIdField = "gradeId",
dictCode = "Grade")
@TableField(exist = false)
private Map<String, Object> gradeIdDictMap;
}批量导出
数据导出的过程与列表接口极为相似,唯一重要的差别是导出接口不分页,所以导出结果集中字典数据的批量翻译和绑定,对于导出接口的效率提升,将会更为行之有效。
@PostMapping("/export")
public void export(
@MyRequestBody VideoTransStatsDto videoTransStatsDtoFilter,
@MyRequestBody MyOrderParam orderParam) throws IOException {
// ... ... 略过其他字典字段的验证逻辑若干行。
// 这个方法和上面示例中,接口接口/list的关联查询的方法是一致的。都是先获取主表数据,在批量
// 从redis缓存中获取字典数据,再组装到返回的数据集中。由于导出没有分页,所以这种批量字典翻译,
// 对导出接口的性能提升,会更有帮助的。
List<VideoTransStats> resultList =
videoTransStatsService.getVideoTransStatsListWithRelation(videoTransStatsFilter, orderBy);
ExportUtil.doExport(resultList, headerMap, "videoTransStats.xlsx");
}批量导入
批量导入时,为了显著提升导入接口的执行效率,降低对系统运行时的瞬时冲击,我们采用了字典数据批量验证的实现方式。下面的示例会先给出导入接口 (/import) 的代码。其中调用的 verifyImportList 方法实现了字典数据的批量验证逻辑。
// 下面的importBatch方法位于Controller类内。
@PostMapping("/import")
public ResponseResult<Void> importBatch(
@RequestParam Boolean skipHeader,
@RequestParam("importFile") MultipartFile importFile) throws Exception {
// ... ... 这里忽略若干行参数验证的代码。
// 重点!!!CourseService.verifyImportList 实现了字典数据的批量验证逻辑。
CallResult result = courseService.verifyImportList(dataList, null);
if (!result.isSuccess()) {
return ResponseResult.errorFrom(result);
}
courseService.saveNewBatch(dataList, -1);
return ResponseResult.success();
}// 以下代码位于业务的ServiceImpl类内。主要功能是批量验证字典数据的合法性,批量验证可以极大的提升运行时效率。
@Override
public CallResult verifyImportList(List<Course> dataList, Set<String> ignoreFieldSet) {
// ... ... 略过其他字典字段的验证逻辑若干行。
CallResult callResult;
if (!CollUtil.contains(ignoreFieldSet, "gradeId")) {
// 下面调用的verifyImportForGlobalDict方法的代码位于基类BaseService中。
// 该方法会从缓存或数据表中,一次性读取所需的字典数据列表,并在内存中完成验证比对。
// 这样可以显著的降低网络开销,以及与Redis或数据库的交互次数,从而大幅提升导入的效率。
callResult = verifyImportForGlobalDict(dataList, "gradeIdDictMap", Course::getGradeId);
if (!callResult.isSuccess()) {
return callResult;
}
}
return CallResult.ok();
}统计查询
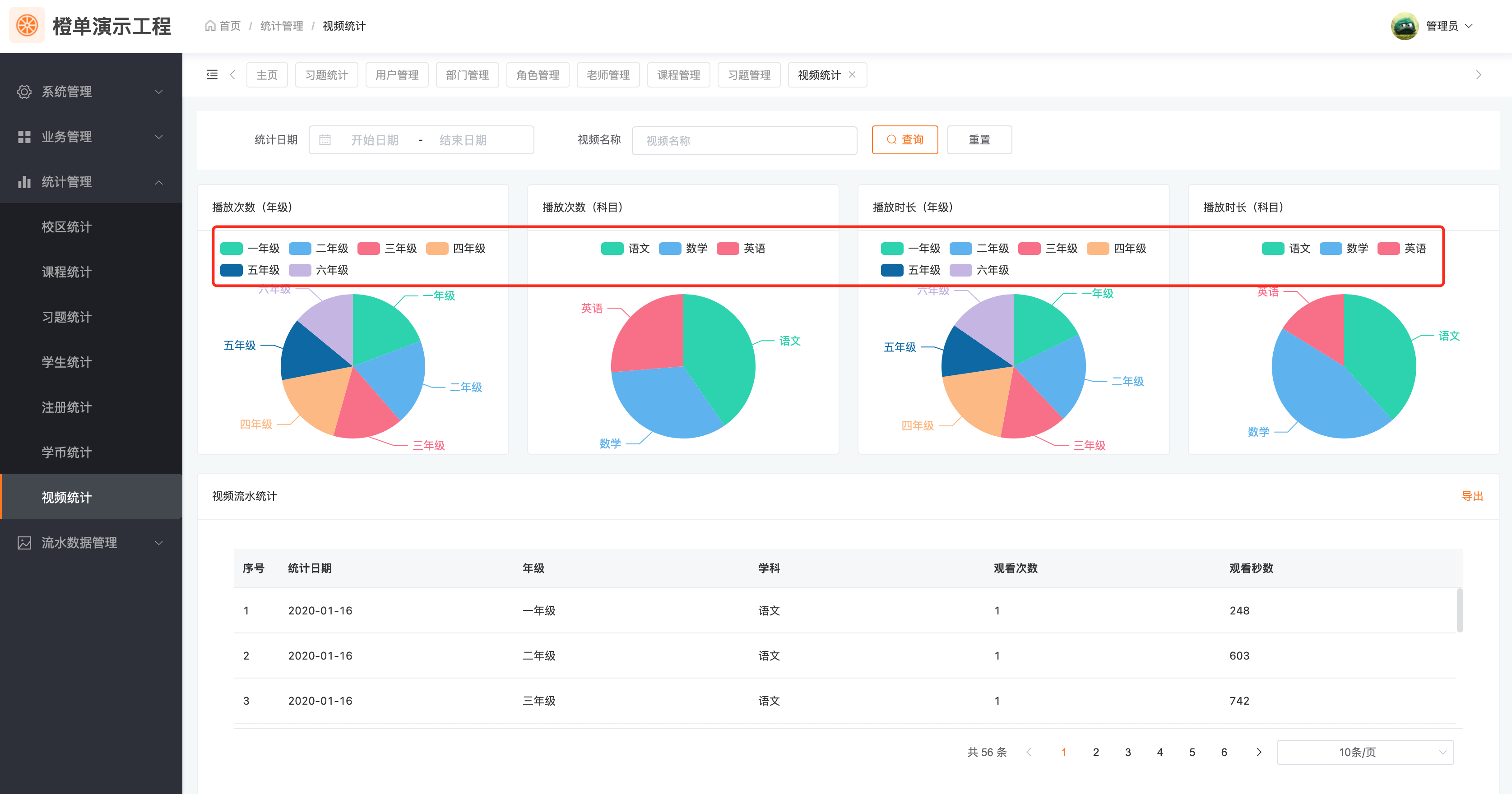
举个饼图的例子,图表中的数据分布来自于指标数据,而 Legend 则为分组维度数据。

上图简化后的 SQL 如下。
SELECT
-- 这里的grade_id是分组维度字段。
grade_id,
-- 饼图中的统计指标值。
SUM(consume_coin) sumOfConsumeCoin
FROM zz_exercise_stats
GROUP BY grade_id上图中 Legend 使用的是「一年级、二年级 ... …」等显示文本,而非 GROUP BY 从句中的分组字段 grade_id。这是因为我们并没有将统计结果集直接返回给前端,而是在 Java 代码中,对维度字段 gradeId 先进行了字典翻译处理,之后再返回到前端的,具体代码如下。
// 这里是橙单自动生成的 /listWithGroup 接口的代码,该接口专门服务于图表数据。
@PostMapping("/listWithGroup")
public ResponseResult<MyPageData<ExerciseStatsVo>> listWithGroup(
@MyRequestBody ExerciseStatsDto exerciseStatsDtoFilter,
@MyRequestBody(required = true) MyGroupParam groupParam,
@MyRequestBody MyOrderParam orderParam,
@MyRequestBody MyPageParam pageParam) {
// ... ... 这里忽略若干参数验证,分页和排序从句的相关代码。
// 这个方法的实现,会在下面的代码片段中给出。
// getGroupedExerciseStatsListWithRelation方式实现了统计结果的查询,以及维度数据的字典翻译。
List<ExerciseStats> resultList = exerciseStatsService.getGroupedExerciseStatsListWithRelation(
filter, criteria.getGroupSelect(), criteria.getGroupBy(), orderBy);
// 分页连同对象数据转换copy工作,下面的方法一并完成。
return ResponseResult.success(MyPageUtil.makeResponseData(resultList, ExerciseStats.INSTANCE));
}public List<ExerciseStats> getGroupedExerciseStatsListWithRelation(
ExerciseStats filter, String groupSelect, String groupBy, String orderBy) {
// 调用统计SQL,可参考上面简化后的SQL代码段。
List<ExerciseStats> resultList =
exerciseStatsMapper.getGroupedExerciseStatsList(filter, groupSelect, groupBy, orderBy);
// 这里会针对维度字段,如gradeId,进行字典翻译,这个过程应该无需关联数据库了,
// 而是直接从缓存中获取字典数据,然后再在Java代码中进行数据的组装。在执行完下面的代码后,
// 与gradeId关联的gradeName数据,就会出现在resultList中,这个resultList会返回给前端的。
this.buildRelationForDataList(resultList, MyRelationParam.normal());
return resultList;
}为了让整个示例更为完整,我们下面给出对应于分组数据的实体对象定义。
@Data
@TableName(value = "zz_exercise_stats")
public class ExerciseStats {
// ... ... 省略若干其他字段的定义,仅仅给出了简化后的相关字段定义。
@TableField(value = "grade_id")
private Integer gradeId;
// 字典数据关联的注解,上面代码中的buildRelationForDataList方法,会基于
// 该注解实现字典翻译,并将翻译后的字典数据存到该字段。
// NOTE:这个字典格式在橙单生成的代码中是统一的。所以前端也可以统一处理字典翻译数据了。
@RelationGlobalDict(
// 提取当前表中指定字典字段数据。
masterIdField = "gradeId",
// 全局编码字典中的字典编码。
dictCode = "Grade")
@TableField(exist = false)
// 翻译后的字典数据,会存入该Map中,该Map包含两个条目,id和name,
// 分别对应本例的gradeId和gradeName的实际数据值。
private Map<String, Object> gradeIdDictMap;
}字典翻译的优势
在详细介绍字典翻译的优势之前,我们先回顾一下基于传统的 SQL 多表关联方式,是如何获取字典显示数据的。
- 关联独立的字典表。
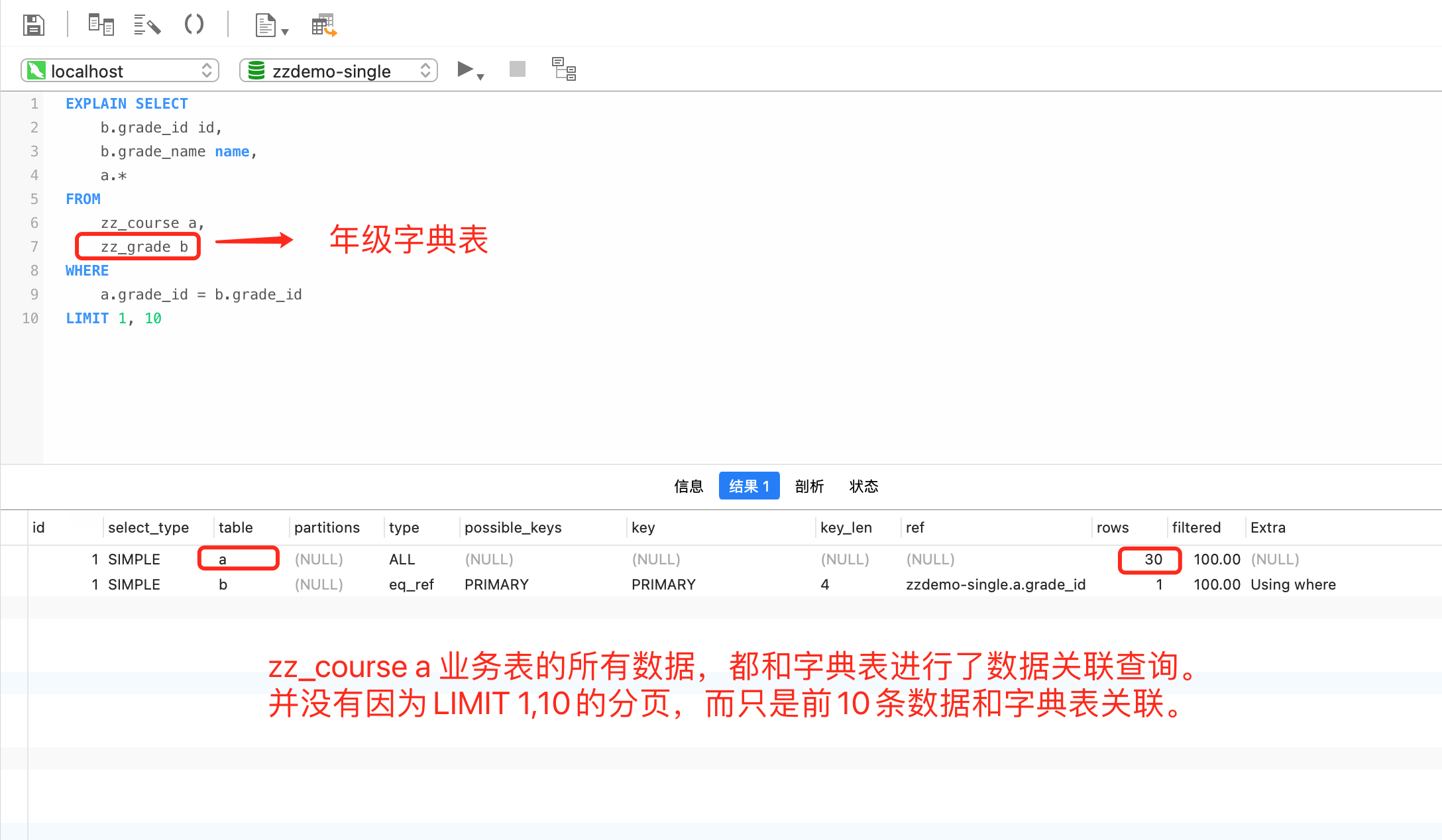
- 关联全局字典表 (zz_global_item_dict),字典之间用不同的编码值字段 (dict_code) 加以区分。
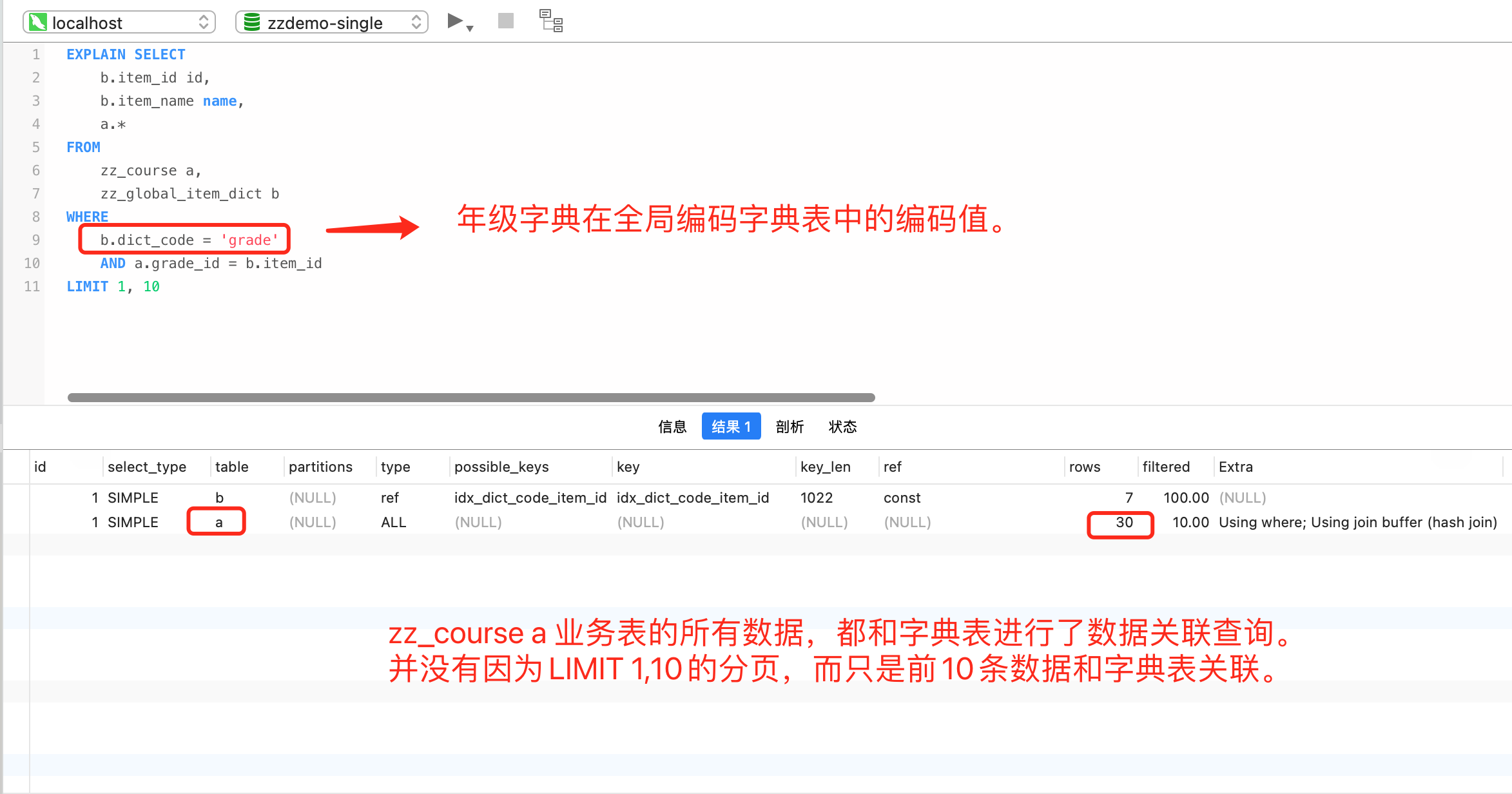
请留意以上截图中的执行计划部分,可以发现一个共同点,业务主表 zz_course 中的所有数据都和字典表 (zz_grade/zz_global_dict_item) 进行了表关联操作,然后再返回分页 (LIMIT 1,10) 后的数据。由此可见,无需返回的数据也参与了多表关联。这种多表关联的 SQL 操作,会随着业务主表数据量的增大,给数据库带来的压力也会逐步提升。
字典翻译
下面是字典翻译实现相关的代码片段。
@Override
public List<Course> getCourseListWithRelation(Course filter, String orderBy) {
// 通过单表查询,从数据库中获取分页后的主表数据列表,如这里的课程列表。
List<Course> resultList = courseMapper.getCourseList(filter, orderBy);
// buildGlobalDictForDataList方法位于父类,会根据实体对象中的字段
// 注解(@RelationGlobalDict),自动实现字典查询和数据绑定。
this.buildGlobalDictForDataList(resultList);
// 返回关联的结果集。
return resultList;
}下面给出 buildGlobalDictForDataList 方法的核心实现和关键性注释。
private void buildGlobalDictForDataList(List<M> resultList) {
// relationGlobalDictStructList是当前实体类中,标有@RelationGlobalDict注解的字段列表。
// 为了保证运行时效率,解析和加载工作,是在服务启动时实现的,具体可参考橙单的线上文档。
if (CollUtil.isEmpty(this.relationGlobalDictStructList) || CollUtil.isEmpty(resultList)) {
return;
}
for (RelationStruct relationStruct : this.relationGlobalDictStructList) {
// 先从单表查询的结果集resultList中,提取出实体类(如课程Course)中字典字段的非空数据值集合,
// 如前例中的年级字典gradeId,最后利用Set集合实现去重。
Set<Object> masterIdSet = resultList.stream()
.map(obj -> ReflectUtil.getFieldValue(obj, relationStruct.masterIdField))
.filter(Objects::nonNull)
.collect(toSet());
String slaveId = relationStruct.relationDict.slaveIdField();
if (CollectionUtils.isNotEmpty(masterIdSet)) {
// 根据业务主表结果集中的字典数据列表,如gradeIds,利用gradeService.getInList方法,
// 从缓存中批量读取指定Id的数据。
relationList = relationStruct.service.getInList(slaveId, masterIdSet);
}
// 最后的工作就是数据组装,将迭代业务主表的结果集resultList,然后将匹配的字典字典,
// 赋值给主表实体对象(如课程Course)中的字典翻译后的关联字段中,如gradeIdDictMap。
// 默认的规则是字典字段gradeId后面加DictMap的后缀。类型为Map,包含两个数据entry,
// 分别是id和name。
// 这里就不在展开了,有兴趣的参考橙单码云开源仓库中的代码。
// https://gitee.com/orangeform/orange-admin
MyModelUtil.makeDictRelation(
modelClass, resultList, relationList, relationStruct.relationField.getName());
}
}下面是业务服务 (Java 代码) 中的处理步骤。
- 单表查询业务主表数据,如 zz_course,数据库只返回分页后的主表数据。
- 提取分页后结果集中的字典字段值并去重,如 zz_course.grade_id 字段。
- 将上一步中的 grade_id 集合,批量提交至 Redis 缓存,查询并返回所有关联的字典数据。
- 最后将 Redis 返回的字典数据和业务主表数据进行绑定,并将结果返回给前端。
综合比对
- 系统性能。在高并发系统中,数据库通常都会成为拉低系统吞吐量的主要因素。与此同时,由于数据库存有大量的业务数据,因此其横向扩充的能力也是最差的。我们通过尽可能使用单表查询的优化策略,可以显著降低数据库的计算压力与网络开销,从而提升整个业务系统的并发处理能力。
- 架构弹性。业务数据和字典数据组装的处理逻辑,我们放到了业务服务 (Java 代码) 中实现,由于是无状态操作,因此横向弹性扩展能力极好,可以做到按需调整业务服务的 Docker 容器数量。
- 分库分表。拆分后,如果业务表和字典表需要同库,那么字典表数据的维护需要同步到所有数据库一份。如果不同库,原有的表关联 SQL 代码全部作废。而对于单表查询后的字典翻译方式,代码实现没有任何影响。
- 代码可读性。在橙单中我们通过给实体类字段添加 @RelationDict 系列的注解,让开发者在开发过程中,可以一目了然的看到哪些字段是字典字段,以及他们之间的关联关系。更值得一提的是,在上线后长期的代码维护中,这种直观的注解方式,对于后续代码维护者来说,可以做到更快的上手。
- 数据接口统一。通过上一小节的示例代码可以发现,所有字典数据都是按照 id 和 name 的统一格式返回的,这样前端代码可以在前端拦截器中,对字典数据做统一的逻辑处理,从而进一步降低前后端沟通和联调的成本。反之 SQL 关联方式,当项目工期紧急时,大部分开发者很难保证全部按照统一的规范去约束每一个与字典相关接口的数据返回格式的。
压测性能比对
测试的接口是教学版中的知识点列表接口,知识点表 (zz_knowledge) 包含两个字典字段,年级 (zz_grade) 和 教材版本 (zz_material_edition)。在下面的压测用例中,我们基于不同的业务表数据量和不同的线程并发数,各循环 50 次。统计指标是「总耗时/平均耗时 (ms)」。
- 通过 SQL 关联方式的查询字典数据。
| 并发数 (5) | 并发数 (10) | 并发数 (15) | 并发数 (20) | 并发数 (25) | |
|---|---|---|---|---|---|
| 业务表数据量 (100) | 15300/61 | 723000/144 | 116000/155 | 222000/222 | 280000/222 |
| 业务表数据量 (10000) | 22600/90 | 118000/237 | 158000/211 | 318000/318 | 423000/338 |
| 业务表数据量 (100000) | 47000/188 | 124000/249 | 252000/336 | 394000/394 | 690000/551 |
- 单表查询主表,Java 代码从 Redis 缓存读取字典数据并完成数据组装。
| 并发数 (5) | 并发数 (10) | 并发数 (15) | 并发数 (20) | 并发数 (25) | |
|---|---|---|---|---|---|
| 业务表数据量 (100) | 21000/84 | 76700/153 | 117000/156 | 224000/224 | 290000/232 |
| 业务表数据量 (10000) | 19200/77 | 63700/127 | 137000/183 | 192000/192 | 317000/253 |
| 业务表数据量 (100000) | 28300/113 | 90400/180 | 216000/288 | 317000/317 | 476000/380 |
压测结论
数据量小、并发请求低的情况下,业务表基于 SQL 关联字典表的方式 (表格一) 效率更高,这个很好理解,MySQL 都是 C/C++ 开发的,算法更优效率更高。而单表查询,Java 代码再次从 Redis 查询并完成数据组装的方式 (表格二),多了一次到 Redis 的网络开销,而且 Java 实现方式的效率肯定是低于数据库中 C/C++ 的代码实现。而当主表数据和并发请求上来之后,数据库因为表关联查询所引起的效率瓶颈问题,就开始逐渐明显了,而基于 Java 业务代码进行字典翻译的模式,因此而受到的影响,会明显低于前者 SQL 关联的方式。
结语
赠人玫瑰,手有余香,感谢您的支持和关注,选择橙单,效率乘三,收入翻番。